Building An LSM Engine Part I
I’m writing the posts in this series based on a course I completed. I can’t recommend the course highly enough. If you’re actually interested in really intuiting an LSM engine, I recommend you do the course yourself.
This is a series of posts around building an LSM-based key-value store. It will include flushing memtables to disk, compaction and a very minimal implementation of serializable snapshot isolation (SSI) using Write Snapshot Isolation (WSI). If you want to see the complete code for all sections of this series, check it out here. If you want to see the complete code for only this post, check out this commit. I’m going to follow the pattern of the course, so one post for every week of the course. The commits on my repo follow the same pattern, so you should be able to easily tell which commit to checkout.
Goals
By the end of the post we will have covered the following 3 goals:
- Writing to an in-memory buffer
- Flushing the in-memory buffer to disk
- Running point and range queries on the sources
Introduction
If you want an overview of what LSM trees are and how different components work together without diving into too much code, I recommend looking at this post by Justin Jaffrey and this one by Garren Smith.
Typically, LSM engines have 3 main components:
- The in memory component (memtable)
- Flushing data to disk (sorted string table)
- Combining data from multiple sstables together (compaction)
We’ll cover compaction in a future post.
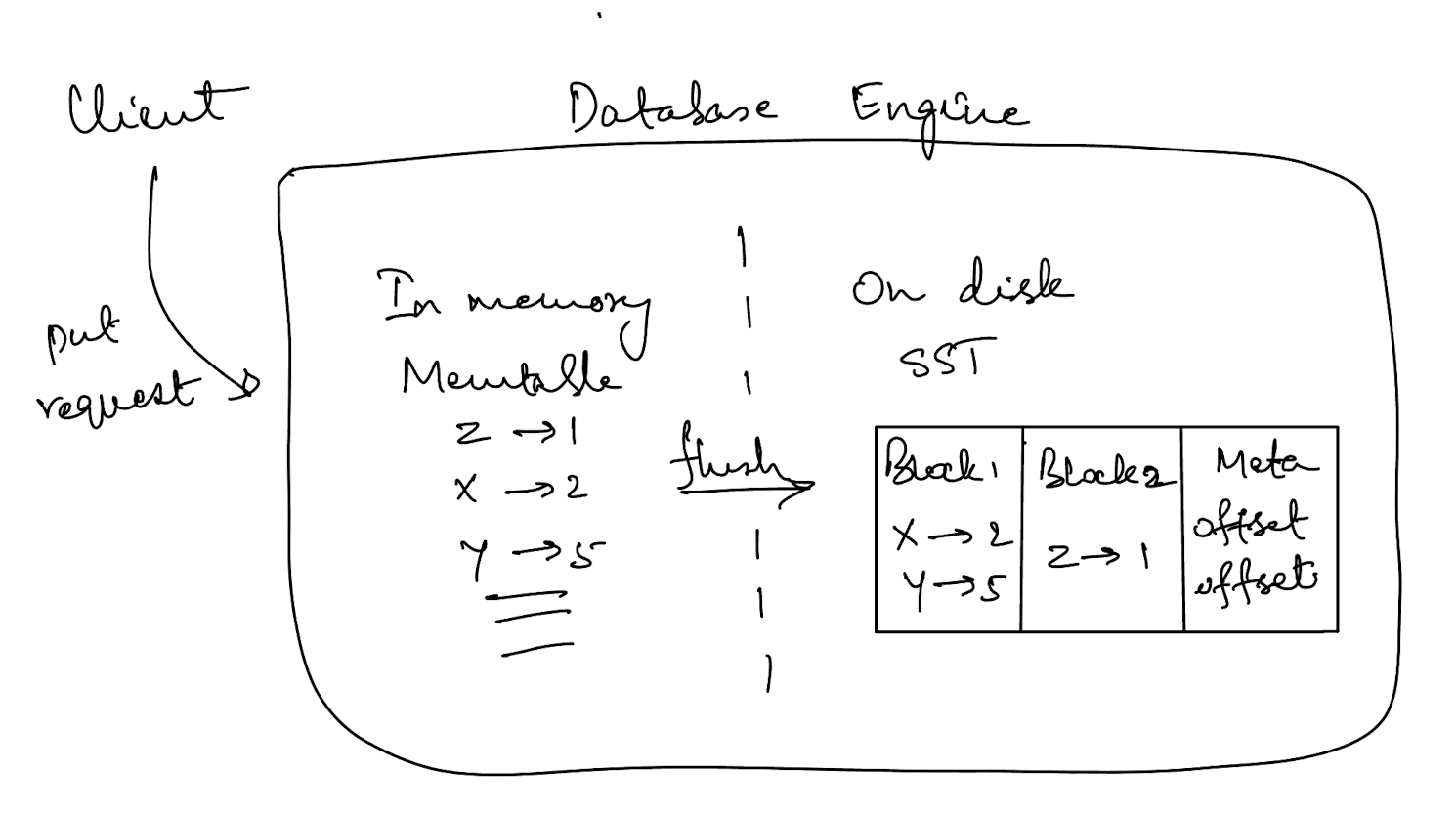
The write path looks like this. Client put request -> add to memtable -> eventually flush to sstable. The eventually flush to SST is usually implementation defined where there is a limit to the memtable buffer. When this buffer is exceeded, the memtable is frozen and then converted to a sorted string table at some later point. Let’s jump into the code.
The Database Engine
We need a database struct that can hold the reference to the memtable and everything else we need. So, let’s define those structs first.
/// A thin wrapper for `LsmStorageInner` and the user interface for MiniLSM.
pub struct MiniLsm {
pub(crate) inner: Arc<LsmStorageInner>,
/// Notifies the L0 flush thread to stop working. (In week 1 day 6)
flush_notifier: crossbeam_channel::Sender<()>,
/// The handle for the compaction thread. (In week 1 day 6)
flush_thread: Mutex<Option<std::thread::JoinHandle<()>>>,
/// Notifies the compaction thread to stop working. (In week 2)
compaction_notifier: crossbeam_channel::Sender<()>,
/// The handle for the compaction thread. (In week 2)
compaction_thread: Mutex<Option<std::thread::JoinHandle<()>>>,
}
impl Drop for MiniLsm {
fn drop(&mut self) {
self.compaction_notifier.send(()).ok();
self.flush_notifier.send(()).ok();
}
}
impl MiniLsm {
pub fn close(&self) -> Result<()> {
let mut flush_thread = self.flush_thread.lock();
if let Some(flush_thread) = flush_thread.take() {
match flush_thread.join() {
std::result::Result::Ok(_) => (),
Err(e) => eprintln!("flush thread panicked: {:?}", e),
}
}
Ok(())
}
/// Start the storage engine by either loading an existing directory or creating a new one if the directory does
/// not exist.
pub fn open(path: impl AsRef<Path>, options: LsmStorageOptions) -> Result<Arc<Self>> {
let inner = Arc::new(LsmStorageInner::open(path, options)?);
let (tx1, rx) = crossbeam_channel::unbounded();
let compaction_thread = inner.spawn_compaction_thread(rx)?;
let (tx2, rx) = crossbeam_channel::unbounded();
let flush_thread = inner.spawn_flush_thread(rx)?;
Ok(Arc::new(Self {
inner,
flush_notifier: tx2,
flush_thread: Mutex::new(flush_thread),
compaction_notifier: tx1,
compaction_thread: Mutex::new(compaction_thread),
}))
}
}
Now, let’s define the structs for the actual state.
/// Represents the state of the storage engine.
#[derive(Clone)]
pub struct LsmStorageState {
/// The current memtable.
pub memtable: Arc<MemTable>,
/// Immutable memtables, from latest to earliest.
pub imm_memtables: Vec<Arc<MemTable>>,
/// L0 SSTs, from latest to earliest.
pub l0_sstables: Vec<usize>,
/// SsTables sorted by key range; L1 - L_max for leveled compaction, or tiers for tiered
/// compaction.
pub levels: Vec<(usize, Vec<usize>)>,
/// SST objects.
pub sstables: HashMap<usize, Arc<SsTable>>,
}
pub(crate) struct LsmStorageInner {
pub(crate) state: Arc<RwLock<Arc<LsmStorageState>>>,
pub(crate) state_lock: Mutex<()>,
path: PathBuf,
pub(crate) block_cache: Arc<BlockCache>,
next_sst_id: AtomicUsize,
pub(crate) options: Arc<LsmStorageOptions>,
pub(crate) compaction_controller: CompactionController,
pub(crate) manifest: Option<Manifest>,
pub(crate) mvcc: Option<LsmMvccInner>,
pub(crate) compaction_filters: Arc<Mutex<Vec<CompactionFilter>>>,
}
You’ll notice that there are two separate locks here - one for the accessing the LSM state and another which is a simple mutex. The idea is, to increase the write throughput (avoiding time waiting for disk I/O), any time you want to modify the actual state of the LSM engine (think either flushing a memtable or compacting SST’s), you acquire the state_lock mutex in conjunction with the write lock to make the actual changes. Any other time where you just want to write to the memtable, you can do a read lock on state.
If you depended on the write lock alone, you would acquire it and then be stuck waiting for disk I/O while preventing any writes to the memtable resulting in a latency spike.
There are also a few channels set up for cross thread communication - namely for flushing the frozen memtable and for running a compaction.
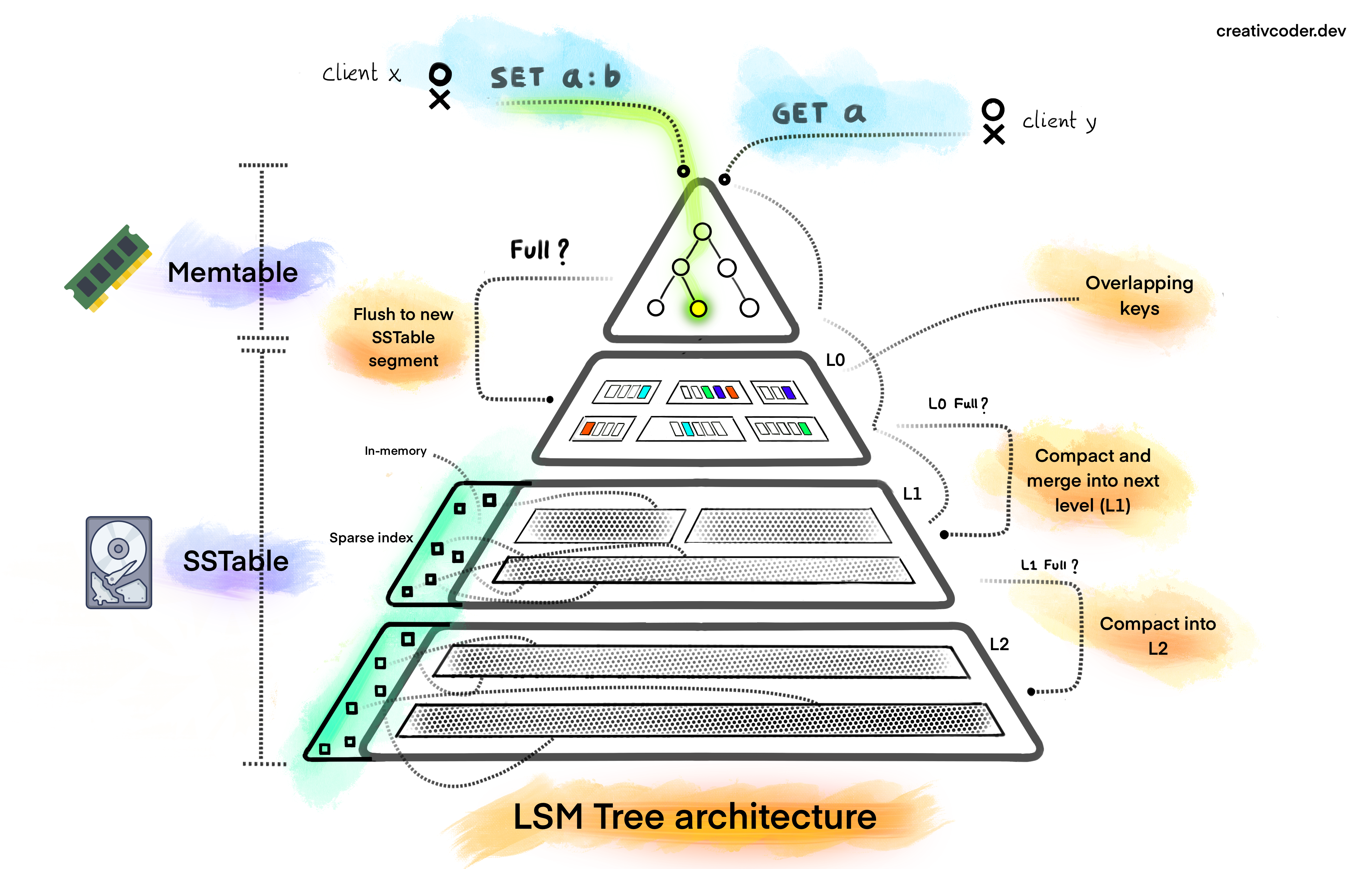 |
|---|
| Source: https://www.creativcoder.dev/blog/what-is-a-lsm-tree |
The MemTable
Here’s the definition for the MemTable.
pub struct MemTable {
id: usize,
map: Arc<SkipMap<KeyBytes, Bytes>>,
approximate_size: Arc<AtomicUsize>,
wal: Option<Wal>,
}
I’m using the crossbeam crate’s implementation of a SkipList. It supports concurrency out of the box, so no need to wrap it in a mutex. Also, all key value pairs will be written as bytes and the bytes crate provides an implementation which stores references to the underlying bytes on disk, so cloning is cheap.
KeyBytes is a wrapper around bytes::Bytes, which you can understand better by looking at this file in the repo.
The implementation for put and delete on the memtable is relatively straightforward. The delete implementation is LSM engines requires writing a tombstone value for the key, so it just uses the same put interface.
impl Memtable {
pub fn put(&self, _key: &[u8], _value: &[u8]) -> Result<()> {
self.map
.insert(Bytes::from(_key.to_vec()), Bytes::from(_value.to_vec()));
let current_size = self
.approximate_size
.load(std::sync::atomic::Ordering::Relaxed);
let key_value_size = _key.len() + _value.len();
let new_size = current_size + key_value_size;
self.approximate_size
.store(new_size, std::sync::atomic::Ordering::Relaxed);
Ok(())
}
}
Now, the more interesting part here is freezing the memtable, which is handled in LsmStorageInner.
impl LsmStorageInner {
/// Put a key-value pair into the storage by writing into the current memtable.
pub fn put(&self, _key: &[u8], _value: &[u8]) -> Result<()> {
let state = self.state.read();
let result = state.memtable.put(_key, _value);
if state.memtable.approximate_size() >= self.options.target_sst_size {
let state_lock = self.state_lock.lock();
if state.memtable.approximate_size() >= self.options.target_sst_size {
drop(state);
self.force_freeze_memtable(&state_lock)?
}
}
result
}
/// Remove a key from the storage by writing an empty value.
pub fn delete(&self, _key: &[u8]) -> Result<()> {
let state = self.state.read();
let result = state.memtable.put(_key, &[]);
if state.memtable.approximate_size() >= self.options.target_sst_size {
let state_lock = self.state_lock.lock();
if state.memtable.approximate_size() >= self.options.target_sst_size {
drop(state);
self.force_freeze_memtable(&state_lock)?
}
}
result
}
/// Force freeze the current memtable to an immutable memtable
pub fn force_freeze_memtable(&self, _state_lock_observer: &MutexGuard<'_, ()>) -> Result<()> {
let state_read = self.state.read();
let current_memtable = Arc::clone(&state_read.memtable);
drop(state_read);
let new_memtable = Arc::new(MemTable::create(self.next_sst_id()));
let mut state_guard = self.state.write();
let state = Arc::make_mut(&mut state_guard);
state.imm_memtables.insert(0, current_memtable);
state.memtable = new_memtable;
Ok(())
}
}
We make a simple check to determine if the memtable has exceeded the size limit, and if so freeze the memtable and place it inside a vector. More importantly, we need to create a new memtable to accept future writes. For that tiny duration, we obviously can’t accept any new writes.
This is great, so far we can write to the memtable. Now, what if you want to read the value back from the memtable. For now, since our write path consists of only the memtables, we can just iterate over them and check if any of them have the key we are looking for. Currently, we can support point queries but not range queries, so let’s go ahead and support that.
/// Get a key from the storage. In day 7, this can be further optimized by using a bloom filter.
impl LsmStorageInner {
pub fn get(&self, key: &[u8]) -> Result<Option<Bytes>> {
// first probe the memtables
let state_guard = self.state.read();
let mut memtables = Vec::new();
memtables.push(Arc::clone(&state_guard.memtable));
memtables.extend(
state_guard
.imm_memtables
.iter()
.map(|memtable| Arc::clone(memtable)),
);
for memtable in memtables {
if let Some(value) = memtable.get(key) {
if value.is_empty() {
return Ok(None);
}
return Ok(Some(value));
}
}
}
}
This works because, by default, the SkipMap stores data in a sorted order.
Awesome! We have in-memory buffer we can write to and read from. If only we had unlimited memory, but alas!
Sorted String Table
Without infinite memory, let’s turn our attention to on-disk representations for our data. Let’s start building this out visually and then represent that in code. We can put all our data into blocks and then use those blocks as part of a file.
We will also need to store some metadata for the file so that we can quickly tell what portion of the file we want to read. We don’t want to be loading the entire file into memory, especially when we can get away with reading just a specific block within the file.
Here’s the encoding format we will use. We include a bloom filter with each SST to quickly tell us whether a key does not exist in the SST file. This is a great addition because bloom filters can tell us with a 100% certainty whether something does not exist, saving us the I/O of loading any blocks from this file.
If you want to understand bloom filters better, this is a great post by Sam Who
-----------------------------------------------------------------------------------------------------
| Block Section | Meta Section |
-----------------------------------------------------------------------------------------------------
| data block | ... | data block | metadata | meta block offset | bloom filter | bloom filter offset |
| | varlen | u32 | varlen | u32 |
-----------------------------------------------------------------------------------------------------
Now, let’s dive a little deeper and look at what each individual block looks like.
----------------------------------------------------------------------------------------------------
| Data Section | Offset Section | Extra |
----------------------------------------------------------------------------------------------------
| Entry #1 | Entry #2 | ... | Entry #N | Offset #1 | Offset #2 | ... | Offset #N | num_of_elements |
----------------------------------------------------------------------------------------------------
And below is what each entry within a block looks like
-----------------------------------------------------------------------
| Entry #1 | ... |
-----------------------------------------------------------------------
| key_len (2B) | key (keylen) | value_len (2B) | value (varlen) | ... |
-----------------------------------------------------------------------
Let’s represent this in code. First thing is a struct that can help us quickly build individual blocks out. There’s a simple encoding scheme in the block which uses key overlap with the first key to compress the size of the data.
use crate::key::{Key, KeySlice, KeyVec};
use super::Block;
/// Builds a block.
pub struct BlockBuilder {
/// Offsets of each key-value entries.
offsets: Vec<u16>,
/// All serialized key-value pairs in the block.
data: Vec<u8>,
/// The expected block size.
block_size: usize,
/// The first key in the block
first_key: KeyVec,
}
impl BlockBuilder {
/// Creates a new block builder.
pub fn new(block_size: usize) -> Self {
BlockBuilder {
offsets: Vec::new(),
data: Vec::new(),
block_size,
first_key: Key::new(),
}
}
/// Adds a key-value pair to the block. Returns false when the block is full.
#[must_use]
pub fn add(&mut self, key: KeySlice, value: &[u8]) -> bool {
// get the overlap of the key with the first key
let key_overlap = key
.into_inner()
.iter()
.zip(self.first_key.as_key_slice().into_inner().iter())
.take_while(|(a, b)| a == b)
.count() as u16;
let key_overlap_bytes = key_overlap.to_le_bytes();
let rest_of_key = &(key.into_inner())[key_overlap as usize..];
let rest_of_key_len = (rest_of_key.len() as u16).to_le_bytes();
let value_length = value.len();
let value_length_bytes = (value_length as u16).to_le_bytes();
let entry_size = 2 + rest_of_key.len() + 2 + value_length + 2;
if self.data.len() + self.offsets.len() + entry_size > self.block_size
&& self.first_key.raw_ref().len() > 0
{
return false;
}
self.offsets.push(self.data.len() as u16);
self.data.extend_from_slice(&key_overlap_bytes);
self.data.extend_from_slice(&rest_of_key_len);
self.data.extend_from_slice(rest_of_key);
self.data.extend_from_slice(&value_length_bytes);
self.data.extend_from_slice(value);
if self.first_key.raw_ref().len() == 0 {
let mut new_key = Key::new();
new_key.set_from_slice(key);
self.first_key = new_key;
}
true
}
/// Check if there is no key-value pair in the block.
pub fn is_empty(&self) -> bool {
self.offsets.is_empty()
}
/// Finalize the block.
pub fn build(self) -> Block {
Block {
data: self.data,
offsets: self.offsets,
}
}
pub fn size(&self) -> usize {
self.offsets.len()
}
}
Next, we need a struct that can help us build out an SSTable in a similar fashion by using the block builder
use std::path::Path;
use std::sync::Arc;
use anyhow::Result;
use super::{bloom::Bloom, BlockMeta, FileObject, SsTable};
use crate::{
block::{Block, BlockBuilder},
key::{Key, KeySlice},
lsm_storage::BlockCache,
};
/// Builds an SSTable from key-value pairs.
pub struct SsTableBuilder {
builder: BlockBuilder,
first_key: Vec<u8>,
last_key: Vec<u8>,
data: Vec<u8>,
pub(crate) meta: Vec<BlockMeta>,
block_size: usize,
key_hashes: Vec<u32>,
}
impl SsTableBuilder {
/// Create a builder based on target block size.
pub fn new(block_size: usize) -> Self {
SsTableBuilder {
builder: BlockBuilder::new(block_size),
first_key: Vec::new(),
last_key: Vec::new(),
data: Vec::new(),
meta: Vec::new(),
block_size,
key_hashes: Vec::new(),
}
}
/// Adds a key-value pair to SSTable.
///
/// Note: You should split a new block when the current block is full.(`std::mem::replace` may
/// be helpful here)
pub fn add(&mut self, key: KeySlice, value: &[u8]) {
if self.first_key.is_empty() {
self.first_key = key.to_key_vec().raw_ref().to_vec();
}
self.key_hashes
.push(farmhash::fingerprint32(key.into_inner()));
if self.builder.add(key, value) {
self.last_key = key.to_key_vec().raw_ref().to_vec();
return;
}
self.freeze_block();
assert!(self.builder.add(key, value));
self.first_key = key.to_key_vec().raw_ref().to_vec();
self.last_key = key.to_key_vec().raw_ref().to_vec();
}
/// This function will take current block builder, build it and replace it with a fresh block builder
/// It will add the block to the SSTable data and then create and store the metadata for this block
fn freeze_block(&mut self) {
// the block is full, split block and replace older builder
let builder = std::mem::replace(&mut self.builder, BlockBuilder::new(self.block_size));
let block = builder.build();
let encoded_block = Block::encode(&block);
// get metadata for split block
let block_meta = BlockMeta {
offset: self.data.len(),
first_key: Key::from_vec(self.first_key.clone()).into_key_bytes(),
last_key: Key::from_vec(self.last_key.clone()).into_key_bytes(),
};
self.data.extend_from_slice(&encoded_block);
self.meta.push(block_meta);
}
/// Get the estimated size of the SSTable.
///
/// Since the data blocks contain much more data than meta blocks, just return the size of data
/// blocks here.
pub fn estimated_size(&self) -> usize {
self.data.len()
}
/// Builds the SSTable and writes it to the given path. Use the `FileObject` structure to manipulate the disk objects.
pub fn build(
mut self,
id: usize,
block_cache: Option<Arc<BlockCache>>,
path: impl AsRef<Path>,
) -> Result<SsTable> {
self.freeze_block();
// create the bloom filter
let bits_per_key = Bloom::bloom_bits_per_key(self.key_hashes.len(), 0.01);
let bloom_filter = Bloom::build_from_key_hashes(&self.key_hashes, bits_per_key);
let mut encoded_sst: Vec<u8> = Vec::new();
encoded_sst.extend_from_slice(&self.data);
// encode meta section for each block and add it to encoding
let mut encoded_meta: Vec<u8> = Vec::new();
BlockMeta::encode_block_meta(&self.meta, &mut encoded_meta);
encoded_sst.extend_from_slice(&encoded_meta);
// encode the meta block offset in the next 4 bytes
let data_len = (self.data.len() as u32).to_le_bytes();
encoded_sst.extend_from_slice(&data_len);
// encode the bloom filter and add it to encoded table
let bloom_filter_offset = encoded_sst.len() as u32;
bloom_filter.encode(&mut encoded_sst);
encoded_sst.extend_from_slice(&bloom_filter_offset.to_le_bytes());
// write the entire encoding to disk
let file = FileObject::create(path.as_ref(), encoded_sst)?;
Ok(SsTable {
file,
block_meta_offset: self.data.len(),
id,
block_cache: None,
first_key: self.meta.first().unwrap().first_key.clone(),
last_key: self.meta.last().unwrap().last_key.clone(),
block_meta: self.meta,
bloom: Some(bloom_filter),
max_ts: 0,
})
}
#[cfg(test)]
pub(crate) fn build_for_test(self, path: impl AsRef<Path>) -> Result<SsTable> {
self.build(0, None, path)
}
}
Now, there’s a couple of missing pieces regarding the encoding & decoding of the table and the blocks, so let’s fill those out. Here’s the encoding and decoding for the block.
#[derive(Clone, Debug, PartialEq, Eq)]
pub struct BlockMeta {
/// Offset of this data block.
pub offset: usize,
/// The first key of the data block.
pub first_key: KeyBytes,
/// The last key of the data block.
pub last_key: KeyBytes,
}
impl BlockMeta {
/// Encode block meta to a buffer.
/// You may add extra fields to the buffer,
/// in order to help keep track of `first_key` when decoding from the same buffer in the future.
pub fn encode_block_meta(block_meta: &[BlockMeta], buf: &mut Vec<u8>) {
for ind_block_meta in block_meta {
let offset_bytes = (ind_block_meta.offset as u16).to_le_bytes();
buf.extend_from_slice(&offset_bytes);
let first_key_length = ind_block_meta.first_key.len() as u16;
let first_key_length_bytes = first_key_length.to_le_bytes();
buf.extend_from_slice(&first_key_length_bytes);
buf.extend_from_slice(ind_block_meta.first_key.raw_ref());
let last_key_length = ind_block_meta.last_key.len() as u16;
let last_key_length_bytes = last_key_length.to_le_bytes();
buf.extend_from_slice(&last_key_length_bytes);
buf.extend_from_slice(ind_block_meta.last_key.raw_ref());
}
}
/// Decode block meta from a buffer.
pub fn decode_block_meta(mut buf: impl Buf) -> Vec<BlockMeta> {
let mut block_metas: Vec<BlockMeta> = Vec::new();
while buf.remaining() > 0 {
let offset = buf.get_u16_le() as usize;
let first_key_length = buf.get_u16_le() as usize;
let mut first_key = vec![0; first_key_length];
buf.copy_to_slice(&mut first_key);
let last_key_length = buf.get_u16_le() as usize;
let mut last_key = vec![0; last_key_length];
buf.copy_to_slice(&mut last_key);
block_metas.push(BlockMeta {
offset,
first_key: Key::from_vec(first_key).into_key_bytes(),
last_key: Key::from_vec(last_key).into_key_bytes(),
});
}
block_metas
}
}
Finally, we need the ability to open a file from disk and decode the bytes. So, let’s add that in as well.
pub(crate) mod bloom;
mod builder;
mod iterator;
use std::fs::File;
use std::path::Path;
use std::sync::Arc;
use anyhow::Result;
pub use builder::SsTableBuilder;
use bytes::Buf;
pub use iterator::SsTableIterator;
use crate::block::Block;
use crate::key::{Key, KeyBytes, KeySlice};
use crate::lsm_storage::BlockCache;
use self::bloom::Bloom;
/// A file object.
pub struct FileObject(Option<File>, u64);
impl FileObject {
pub fn read(&self, offset: u64, len: u64) -> Result<Vec<u8>> {
use std::os::unix::fs::FileExt;
let mut data = vec![0; len as usize];
self.0
.as_ref()
.unwrap()
.read_exact_at(&mut data[..], offset)?;
Ok(data)
}
pub fn size(&self) -> u64 {
self.1
}
/// Create a new file object (day 2) and write the file to the disk (day 4).
pub fn create(path: &Path, data: Vec<u8>) -> Result<Self> {
std::fs::write(path, &data)?;
File::open(path)?.sync_all()?;
Ok(FileObject(
Some(File::options().read(true).write(false).open(path)?),
data.len() as u64,
))
}
pub fn open(path: &Path) -> Result<Self> {
let file = File::options().read(true).write(false).open(path)?;
let size = file.metadata()?.len();
Ok(FileObject(Some(file), size))
}
}
/// An SSTable.
pub struct SsTable {
/// The actual storage unit of SsTable, the format is as above.
pub(crate) file: FileObject,
/// The meta blocks that hold info for data blocks.
pub(crate) block_meta: Vec<BlockMeta>,
/// The offset that indicates the start point of meta blocks in `file`.
pub(crate) block_meta_offset: usize,
id: usize,
block_cache: Option<Arc<BlockCache>>,
first_key: KeyBytes,
last_key: KeyBytes,
pub(crate) bloom: Option<Bloom>,
/// The maximum timestamp stored in this SST, implemented in week 3.
max_ts: u64,
}
impl SsTable {
#[cfg(test)]
pub(crate) fn open_for_test(file: FileObject) -> Result<Self> {
Self::open(0, None, file)
}
/// Open SSTable from a file.
pub fn open(id: usize, block_cache: Option<Arc<BlockCache>>, file: FileObject) -> Result<Self> {
let len = file.size();
// read the last 4 bytes to get the bloom filter offset
let bloom_filter_offset_raw = file.read(len - 4, 4)?;
let bloom_filter_offset = (&bloom_filter_offset_raw[..]).get_u32_le() as u64;
// use the bloom filter offset to read the data starting
let raw_bloom_filter = file.read(bloom_filter_offset, len - bloom_filter_offset - 4)?;
let bloom_filter = Bloom::decode(&raw_bloom_filter)?;
// read the 4 bytes before the bloom offset to get the meta offset
let raw_meta_offset = file.read(bloom_filter_offset - 4, 4)?;
let meta_offset = (&raw_meta_offset[..]).get_u32_le() as u64;
// use the meta offset to read the metadata from the file
let raw_meta = file.read(meta_offset as u64, bloom_filter_offset - 4 - meta_offset)?;
let meta = BlockMeta::decode_block_meta(raw_meta.as_slice());
Ok(SsTable {
file,
block_meta_offset: meta_offset as usize,
id,
block_cache,
first_key: meta.first().unwrap().first_key.clone(),
last_key: meta.last().unwrap().last_key.clone(),
block_meta: meta,
bloom: Some(bloom_filter),
max_ts: 0,
})
}
/// Create a mock SST with only first key + last key metadata
pub fn create_meta_only(
id: usize,
file_size: u64,
first_key: KeyBytes,
last_key: KeyBytes,
) -> Self {
Self {
file: FileObject(None, file_size),
block_meta: vec![],
block_meta_offset: 0,
id,
block_cache: None,
first_key,
last_key,
bloom: None,
max_ts: 0,
}
}
/// Read a block from the disk.
pub fn read_block(&self, block_idx: usize) -> Result<Arc<Block>> {
let block_offset_start = self.block_meta[block_idx].offset;
let block_offset_end = if block_idx + 1 < self.block_meta.len() {
self.block_meta[block_idx + 1].offset
} else {
self.block_meta_offset
};
let block_len = block_offset_end - block_offset_start;
let block_data_raw = self
.file
.read(block_offset_start as u64, block_len as u64)?;
let block_data = Block::decode(&block_data_raw);
Ok(Arc::new(block_data))
}
/// Read a block from disk, with block cache. (Day 4)
pub fn read_block_cached(&self, block_idx: usize) -> Result<Arc<Block>> {
if let Some(block_cache) = &self.block_cache {
let block = block_cache
.try_get_with((self.id, block_idx), || self.read_block(block_idx))
.map_err(|e| {
println!("Error: {:?}", e);
anyhow::anyhow!(e)
})?;
Ok(block)
} else {
self.read_block(block_idx)
}
}
/// Find the block that may contain `key`.
/// Note: You may want to make use of the `first_key` stored in `BlockMeta`.
/// You may also assume the key-value pairs stored in each consecutive block are sorted.
pub fn find_block_idx(&self, key: KeySlice) -> usize {
self.block_meta
.partition_point(|meta| meta.first_key.as_key_slice() <= key) // parition_point does binary search
.saturating_sub(1)
}
/// Get number of data blocks.
pub fn num_of_blocks(&self) -> usize {
self.block_meta.len()
}
pub fn first_key(&self) -> &KeyBytes {
&self.first_key
}
pub fn last_key(&self) -> &KeyBytes {
&self.last_key
}
pub fn table_size(&self) -> u64 {
self.file.1
}
pub fn sst_id(&self) -> usize {
self.id
}
pub fn max_ts(&self) -> u64 {
self.max_ts
}
}
Now, we need to wire this all up back to our storage engine. We will have a flush thread running which executes every X number of milliseconds and it will pick the oldest frozen memtable and attempt to flush that.
Don’t worry about the fact that the sstable is pushed into something called L0, we’ll get to that later.
impl LsmStorageInner {
/// Force flush the earliest-created immutable memtable to disk
pub fn force_flush_next_imm_memtable(&self) -> Result<()> {
let _state_lock = self.state_lock.lock();
let oldest_memtable = {
let state_guard = self.state.write();
let oldest_memtable = state_guard
.imm_memtables
.last()
.expect("No memtable found")
.clone();
oldest_memtable
};
let mut sst_builder = SsTableBuilder::new(self.options.block_size);
oldest_memtable.flush(&mut sst_builder)?;
let sst = Arc::new(sst_builder.build(
oldest_memtable.id(),
Some(Arc::clone(&self.block_cache)),
self.path_of_sst(oldest_memtable.id()),
)?);
{
let mut state_guard = self.state.write();
let mut snapshot = state_guard.as_ref().clone();
let oldest_memtable = snapshot.imm_memtables.pop().expect("No memtable found");
snapshot.l0_sstables.insert(0, oldest_memtable.id());
snapshot.sstables.insert(oldest_memtable.id(), sst);
*state_guard = Arc::new(snapshot);
}
Ok(())
}
fn trigger_flush(&self) -> Result<()> {
{
let state_guard = self.state.read();
if state_guard.imm_memtables.len() < self.options.num_memtable_limit {
return Ok(());
}
}
self.force_flush_next_imm_memtable()?;
Ok(())
}
pub(crate) fn spawn_flush_thread(
self: &Arc<Self>,
rx: crossbeam_channel::Receiver<()>,
) -> Result<Option<std::thread::JoinHandle<()>>> {
let this = self.clone();
let handle = std::thread::spawn(move || {
let ticker = crossbeam_channel::tick(Duration::from_millis(50));
loop {
crossbeam_channel::select! {
recv(ticker) -> _ => if let Err(e) = this.trigger_flush() {
eprintln!("flush failed: {}", e);
},
recv(rx) -> _ => return
}
}
});
Ok(Some(handle))
}
}
Great! We now have the mechanism to take our frozen memtable, write that to a disk friendly format, encode it and then read it back if we want to later.
Now, we already have a mechanism to read back from the memtable, so we also need a way to read back from an SSTable. For the memtable we just iterated over all the memtables in reverse chronological order and checked if we could find the key. The first instance we found was the key we were looking for.
We could do the exact same thing with the SSTables as well. First check memtables for the key and if it can’t be found there start checking the SSTables one by one, and that would actually work fine. However, let’s make this a bit more efficient in a way we can also support range queries.
It’s Iterators All The Way Down
Assume that we have a database engine that ends up in the following state.
put("x", 5)
put("y", 3)
put("x", Tombstone)
// freeze and flush occurs
put("x", 9)
put("y", 3)
put("y", 1)
// freeze and flush occurs
put("a", 12)
put("b", Tombstone)
Now, at this point the state looks like
memtable ("a" -> 12, "b" -> Tombstone)
l0 -> sst1 ("x" -> 9, "y" -> 3, "y" -> 1), sst2 ("x" -> 5, "y" -> 3, "x" -> Tombstone)
We have two different data sources here and if a user wanted to get all the key-value pairs in storage, we would have to iterate over every source simultaneously and figure out what the correct value for it is.
So, let’s define a trait that an iterator over any data source would need to stick to. This makes it easier to define new iterators as and when required.
pub trait StorageIterator {
type KeyType<'a>: PartialEq + Eq + PartialOrd + Ord
where
Self: 'a;
/// Get the current value.
fn value(&self) -> &[u8];
/// Get the current key.
fn key(&self) -> Self::KeyType<'_>;
/// Check if the current iterator is valid.
fn is_valid(&self) -> bool;
/// Move to the next position.
fn next(&mut self) -> anyhow::Result<()>;
/// Number of underlying active iterators for this iterator.
fn num_active_iterators(&self) -> usize {
1
}
}
The trait has an associated type for the type of key it returns.
MemTable Scan
So, let’s go ahead and define the memtable iterator first so that we can do a scan across a memtable.
type SkipMapRangeIter<'a> =
crossbeam_skiplist::map::Range<'a, Bytes, (Bound<Bytes>, Bound<Bytes>), Bytes, Bytes>;
#[self_referencing]
pub struct MemTableIterator {
/// Stores a reference to the skipmap.
map: Arc<SkipMap<Bytes, Bytes>>,
/// Stores a skipmap iterator that refers to the lifetime of `MemTableIterator` itself.
#[borrows(map)]
#[not_covariant]
iter: SkipMapRangeIter<'this>,
/// Stores the current key-value pair.
item: (Bytes, Bytes),
}
impl StorageIterator for MemTableIterator {
type KeyType<'a> = KeySlice<'a>;
fn value(&self) -> &[u8] {
self.with_item(|item| &item.1)
}
fn key(&self) -> KeySlice {
let key = self.with_item(|item| &item.0);
Key::from_slice(key)
}
fn is_valid(&self) -> bool {
!self.with_item(|item| item.0.is_empty())
}
fn next(&mut self) -> Result<()> {
let next_entry = self.with_iter_mut(|iter| {
iter.next()
.map(|entry| (entry.key().clone(), entry.value().clone()))
.unwrap_or_else(|| (Bytes::from_static(&[]), Bytes::from_static(&[])))
});
self.with_item_mut(|item| *item = next_entry);
Ok(())
}
}
impl MemTable {
/// Get an iterator over a range of keys.
pub fn scan(&self, _lower: Bound<&[u8]>, _upper: Bound<&[u8]>) -> MemTableIterator {
let mut iterator = MemTableIteratorBuilder {
map: self.map.clone(),
iter_builder: |map| map.range((map_bound(_lower), map_bound(_upper))),
item: (Bytes::new(), Bytes::new()),
}
.build();
iterator.next().unwrap();
iterator
}
}
So, this was relatively simple to do because we can build an iterator using the Range operator provided by crossbeam.
SSTable Scan
Okay, now we need something that can scan the sorted string table. Now, when scanning an SSTable, each SSTable is composed of individual blocks and those blocks are composed of key-value pairs, so we actually need 2 iterators - one for a block and one for a table itself.
Let’s define the one for the block first. There’s nothing fancy in this iterator, at it’s heart it uses binary search to look through the list of keys. However, since we’re dealing with raw bytes, there’s a fair amount of decoding that goes on here.
use std::sync::Arc;
use bytes::Buf;
use crate::key::{KeySlice, KeyVec};
use super::Block;
/// Iterates on a block.
pub struct BlockIterator {
/// The internal `Block`, wrapped by an `Arc`
block: Arc<Block>,
/// The current key, empty represents the iterator is invalid
key: KeyVec,
/// the value range from the block
value_range: (usize, usize),
/// Current index of the key-value pair, should be in range of [0, num_of_elements)
idx: usize,
/// The first key in the block
first_key: KeyVec,
}
impl BlockIterator {
fn new(block: Arc<Block>) -> Self {
Self {
first_key: BlockIterator::decode_first_key(&block),
block,
key: KeyVec::new(),
value_range: (0, 0),
idx: 0,
}
}
fn decode_first_key(block: &Arc<Block>) -> KeyVec {
let mut buf = &block.data[..];
let overlap_length = buf.get_u16_le(); // read the overlap length (should be 0)
assert_eq!(overlap_length, 0);
let key_length = buf.get_u16_le(); // read the key length
let key = &buf[..key_length as usize];
KeyVec::from_vec(key.to_vec())
}
/// Creates a block iterator and seek to the first entry.
pub fn create_and_seek_to_first(block: Arc<Block>) -> Self {
let mut iter = BlockIterator::new(block);
iter.seek_to_first();
iter
}
/// Creates a block iterator and seek to the first key that >= `key`.
pub fn create_and_seek_to_key(block: Arc<Block>, key: KeySlice) -> Self {
let mut iter = BlockIterator::new(block);
iter.seek_to_key(key);
iter
}
/// Returns the key of the current entry.
pub fn key(&self) -> KeySlice {
self.key.as_key_slice()
}
/// Returns the value of the current entry.
pub fn value(&self) -> &[u8] {
let value_range = self.value_range;
let value_raw = &self.block.data[value_range.0..value_range.1];
value_raw
}
/// Returns true if the iterator is valid.
/// Note: You may want to make use of `key`
pub fn is_valid(&self) -> bool {
if self.key.is_empty() {
return false;
}
true
}
/// Seeks to the first key in the block.
pub fn seek_to_first(&mut self) {
self.seek_to(0);
self.idx = 0;
}
fn seek_to(&mut self, index: usize) {
let offset = self.block.offsets[index] as usize;
let data_to_consider = &self.block.data[offset..];
let (key_overlap_length_raw, rest) = data_to_consider.split_at(2);
let key_overlap_length = u16::from_le_bytes(key_overlap_length_raw.try_into().unwrap());
let (key_length_raw, rest) = rest.split_at(2);
let key_length = u16::from_le_bytes(key_length_raw.try_into().unwrap());
let (key, rest) = rest.split_at(key_length as usize);
let key_overlap = &(self.first_key.clone().into_inner())[..key_overlap_length as usize];
let mut full_key = Vec::new();
full_key.extend_from_slice(&key_overlap);
full_key.extend_from_slice(&key);
self.key = KeyVec::from_vec(full_key);
let (value_length_raw, rest) = rest.split_at(2);
let value_length = u16::from_le_bytes(value_length_raw.try_into().unwrap());
let (_, _) = rest.split_at(value_length as usize);
let new_value_start = offset + 2 + 2 + key_length as usize;
self.value_range = (
new_value_start + 2,
new_value_start + 2 + value_length as usize,
);
}
/// Move to the next key in the block.
pub fn next(&mut self) {
self.idx += 1;
if self.idx >= self.block.offsets.len() {
self.key.clear();
self.value_range = (0, 0);
return;
}
self.seek_to(self.idx);
}
/// Seek to the first key that >= `key`.
/// Note: You should assume the key-value pairs in the block are sorted when being added by
/// callers.
pub fn seek_to_key(&mut self, key: KeySlice) {
let mut low = 0;
let mut high = self.block.offsets.len() - 1;
while low <= high {
let mid = low + (high - low) / 2;
self.seek_to(mid);
self.idx = mid;
let mid_key = self.key.as_key_slice();
match mid_key.cmp(&key) {
std::cmp::Ordering::Less => low = mid + 1,
std::cmp::Ordering::Greater => {
if mid == 0 {
break;
}
high = mid - 1;
}
std::cmp::Ordering::Equal => return,
}
}
if low >= self.block.offsets.len() {
self.key.clear();
self.value_range = (0, 0);
return;
}
self.idx = low;
self.seek_to(self.idx);
}
}
Okay, now let’s focus on the table iterator. The table iterator will use the block iterator from above and will determine which block needs to be read. If the iterator just needs to go to the first key, it will read the first block and if the iterator needs to look for a specific key, it will do a binary search on the metadata of the blocks to determine the key.
use std::sync::Arc;
use anyhow::Result;
use super::SsTable;
use crate::{block::BlockIterator, iterators::StorageIterator, key::KeySlice};
/// An iterator over the contents of an SSTable.
pub struct SsTableIterator {
table: Arc<SsTable>,
blk_iter: BlockIterator,
blk_idx: usize,
}
impl SsTableIterator {
/// Create a new iterator and seek to the first key-value pair in the first data block.
pub fn create_and_seek_to_first(table: Arc<SsTable>) -> Result<Self> {
// get the first block from the sstable and build an iterator on top of it
let block = table.read_block_cached(0)?;
let block_iterator = BlockIterator::create_and_seek_to_first(block);
let iter = SsTableIterator {
table,
blk_iter: block_iterator,
blk_idx: 0,
};
Ok(iter)
}
/// Seek to the first key-value pair in the first data block.
pub fn seek_to_first(&mut self) -> Result<()> {
// get metata for first block index
let block = self.table.read_block_cached(0)?;
let block_iterator = BlockIterator::create_and_seek_to_first(block);
self.blk_idx = 0;
self.blk_iter = block_iterator;
Ok(())
}
fn seek_to(table: &Arc<SsTable>, key: KeySlice) -> Result<(usize, BlockIterator)> {
let mut block_index = table.find_block_idx(key);
let block = table.read_block_cached(block_index).unwrap();
let mut block_iter = BlockIterator::create_and_seek_to_key(block, key);
if !block_iter.is_valid() {
block_index += 1;
if block_index < table.num_of_blocks() {
block_iter =
BlockIterator::create_and_seek_to_first(table.read_block_cached(block_index)?);
}
}
Ok((block_index, block_iter))
}
/// Create a new iterator and seek to the first key-value pair which >= `key`.
pub fn create_and_seek_to_key(table: Arc<SsTable>, key: KeySlice) -> Result<Self> {
let (block_index, block_iter) = Self::seek_to(&table, key)?;
let iter = SsTableIterator {
table,
blk_iter: block_iter,
blk_idx: block_index,
};
Ok(iter)
}
/// Seek to the first key-value pair which >= `key`.
/// Note: You probably want to review the handout for detailed explanation when implementing
/// this function.
pub fn seek_to_key(&mut self, key: KeySlice) -> Result<()> {
let (block_index, block_iter) = Self::seek_to(&self.table, key)?;
self.blk_iter = block_iter;
self.blk_idx = block_index;
Ok(())
}
}
impl StorageIterator for SsTableIterator {
type KeyType<'a> = KeySlice<'a>;
/// Return the `key` that's held by the underlying block iterator.
fn key(&self) -> KeySlice {
self.blk_iter.key()
}
/// Return the `value` that's held by the underlying block iterator.
fn value(&self) -> &[u8] {
self.blk_iter.value()
}
/// Return whether the current block iterator is valid or not.
fn is_valid(&self) -> bool {
self.blk_iter.is_valid()
}
/// Move to the next `key` in the block.
/// Note: You may want to check if the current block iterator is valid after the move.
fn next(&mut self) -> Result<()> {
if self.is_valid() {
self.blk_iter.next();
if !self.blk_iter.is_valid() {
self.blk_idx += 1;
if self.blk_idx < self.table.num_of_blocks() {
let new_block = self.table.read_block_cached(self.blk_idx)?;
let new_block_iter = BlockIterator::create_and_seek_to_first(new_block);
self.blk_iter = new_block_iter;
}
}
}
Ok(())
}
}
This is great, we now have two iterators for 2 different types of data - one for the memtable and one for the sstable. But we have multiple iterators for the memtable and multiple iterators for the sstable. We need a way to combine them.
Merging Iterators
Now, we need a way to represent multiple iterators of the same type as one iterator. This is the classic k-way merge algorithm implemented using a min heap.
First, let’s define a custom heap that will compare our keys to determine which key should be the first one.
struct HeapWrapper<I: StorageIterator>(pub usize, pub Box<I>);
impl<I: StorageIterator> PartialEq for HeapWrapper<I> {
fn eq(&self, other: &Self) -> bool {
self.partial_cmp(other).unwrap() == cmp::Ordering::Equal
}
}
impl<I: StorageIterator> Eq for HeapWrapper<I> {}
impl<I: StorageIterator> PartialOrd for HeapWrapper<I> {
#[allow(clippy::non_canonical_partial_ord_impl)]
fn partial_cmp(&self, other: &Self) -> Option<cmp::Ordering> {
match self.1.key().cmp(&other.1.key()) {
cmp::Ordering::Greater => Some(cmp::Ordering::Greater),
cmp::Ordering::Less => Some(cmp::Ordering::Less),
cmp::Ordering::Equal => self.0.partial_cmp(&other.0),
}
.map(|x| x.reverse())
}
}
impl<I: StorageIterator> Ord for HeapWrapper<I> {
fn cmp(&self, other: &Self) -> cmp::Ordering {
self.partial_cmp(other).unwrap()
}
}
Now, we can define the actual merge iterator.
pub struct MergeIterator<I: StorageIterator> {
iters: BinaryHeap<HeapWrapper<I>>,
current: Option<HeapWrapper<I>>,
}
impl<I: StorageIterator> MergeIterator<I> {
pub fn create(iters: Vec<Box<I>>) -> Self {
if iters.len() == 0 {
return MergeIterator {
iters: BinaryHeap::new(),
current: None,
};
}
let mut heap: BinaryHeap<HeapWrapper<I>> = BinaryHeap::new();
// if none of the iterators are valid, just pick the last one as current
if iters.iter().all(|iter| !iter.is_valid()) {
let mut iters = iters;
return MergeIterator {
iters: heap,
current: Some(HeapWrapper(0, iters.pop().unwrap())),
};
}
for (index, iter) in iters.into_iter().enumerate() {
if iter.is_valid() {
let heap_wrapper = HeapWrapper(index, iter);
heap.push(heap_wrapper);
}
}
let current = heap.pop().unwrap();
MergeIterator {
iters: heap,
current: Some(current),
}
}
}
impl<I: 'static + for<'a> StorageIterator<KeyType<'a> = KeySlice<'a>>> StorageIterator
for MergeIterator<I>
{
type KeyType<'a> = KeySlice<'a>;
fn key(&self) -> KeySlice {
self.current.as_ref().unwrap().1.key()
}
fn value(&self) -> &[u8] {
self.current.as_ref().unwrap().1.value()
}
fn is_valid(&self) -> bool {
self.current
.as_ref()
.map(|heap_wrapper| heap_wrapper.1.is_valid())
.unwrap_or(false)
}
fn next(&mut self) -> Result<()> {
let current = self.current.as_mut().unwrap();
// Check if there are any keys that are identical - advance the lower ranked iterators in that case
while let Some(mut heap_wrapper) = self.iters.peek_mut() {
if heap_wrapper.1.key() == current.1.key() {
// The current and the heap top have the same key. Ignore the heap top key because we organised by reverse
// chronological order when building the heap. The value in current should be what's upheld. Advance the top
if let Err(e) = heap_wrapper.1.next() {
PeekMut::pop(heap_wrapper);
return Err(e);
}
if !heap_wrapper.1.is_valid() {
PeekMut::pop(heap_wrapper);
}
} else {
break;
}
}
// advance the current iterator
current.1.next()?;
// check if the current iterator continues to be valid - if not, replace with the top
if !current.1.is_valid() {
if let Some(heap_wrapper) = self.iters.pop() {
self.current = Some(heap_wrapper);
}
return Ok(());
}
// check if the current iterator should be replaced by the top value in the heap
if let Some(mut heap_wrapper) = self.iters.peek_mut() {
if current < &mut heap_wrapper {
std::mem::swap(current, &mut *heap_wrapper);
}
}
Ok(())
}
fn num_active_iterators(&self) -> usize {
let heap_active_iters: usize = self
.iters
.iter()
.map(|iter| iter.1.num_active_iterators())
.sum();
let current_active_iters: usize = self
.current
.iter()
.map(|iter| iter.1.num_active_iterators())
.sum();
heap_active_iters + current_active_iters
}
}
Let’s take a quick break and look at where we’re at in terms of scanning the data right now.
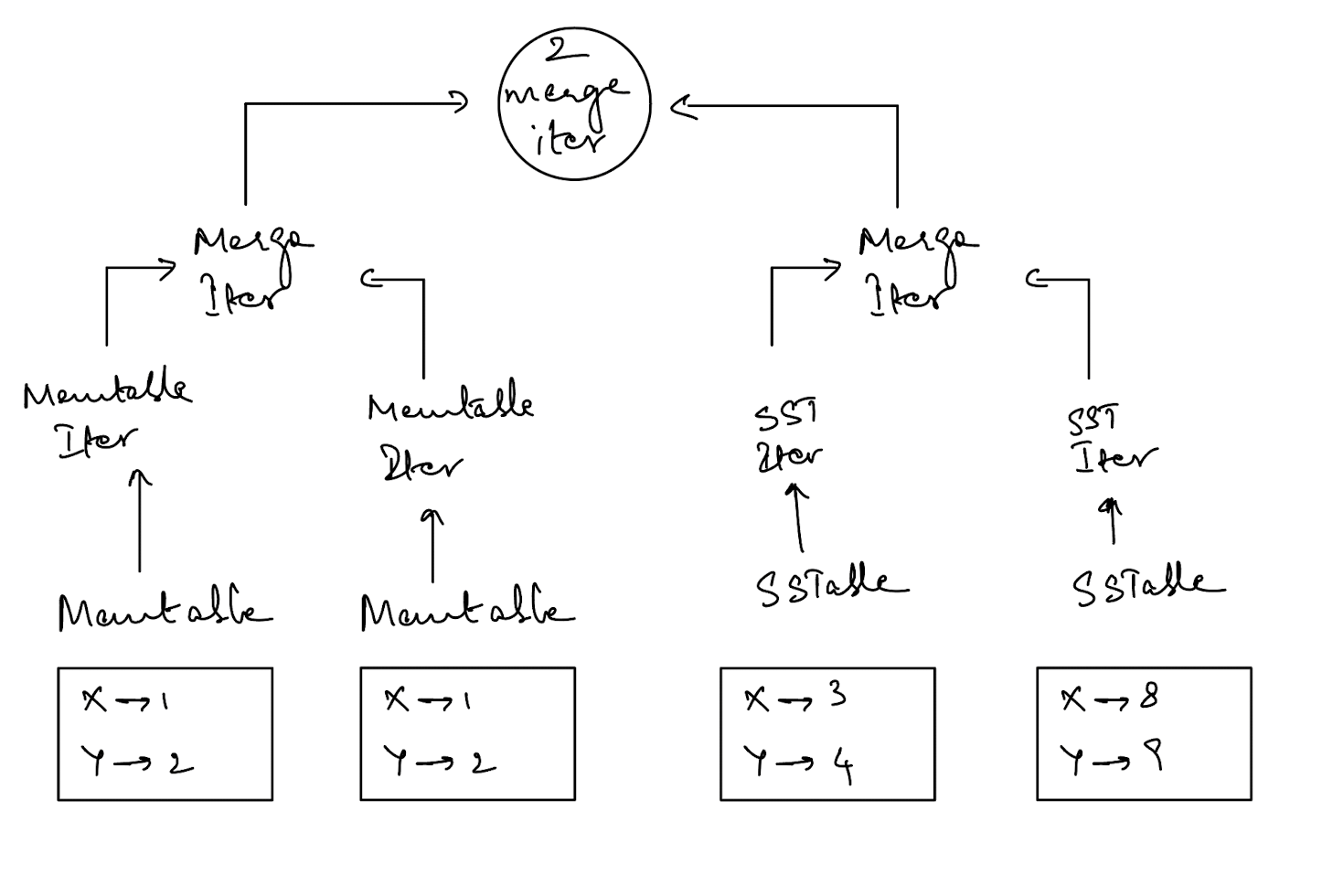
So we have the memtable iterator, the sst iterator & the merge iterator defined. It’s important to note that the order of iterators matters because we always want to check the latest sources of data first - that is the memtables in reverse chronological order and then the sstables in reverse chronological order.
Now, we need one more iterator which can combine two merge iterators into one so that we can search across multiple sources of data in the scan interface - this is the two merge iterator which is defined below.
use anyhow::Result;
use super::StorageIterator;
/// Merges two iterators of different types into one. If the two iterators have the same key, only
/// produce the key once and prefer the entry from A.
pub struct TwoMergeIterator<A: StorageIterator, B: StorageIterator> {
a: A,
b: B,
// Add fields as need
use_iterator: u8, // this can be 0 (use a), 1 (use b), 2 (use both)
}
impl<
A: 'static + StorageIterator,
B: 'static + for<'a> StorageIterator<KeyType<'a> = A::KeyType<'a>>,
> TwoMergeIterator<A, B>
{
pub fn create(a: A, b: B) -> Result<Self> {
let use_iterator = TwoMergeIterator::decide_which_iter_to_use(&a, &b);
Ok(TwoMergeIterator { a, b, use_iterator })
}
fn decide_which_iter_to_use(a: &A, b: &B) -> u8 {
if !a.is_valid() && b.is_valid() {
return 1;
}
if a.is_valid() && !b.is_valid() {
return 0;
}
if !a.is_valid() && !b.is_valid() {
return u8::MAX;
}
if a.key() < b.key() {
0
} else if a.key() > b.key() {
1
} else {
2
}
}
}
impl<
A: 'static + StorageIterator,
B: 'static + for<'a> StorageIterator<KeyType<'a> = A::KeyType<'a>>,
> StorageIterator for TwoMergeIterator<A, B>
{
type KeyType<'a> = A::KeyType<'a>;
fn key(&self) -> Self::KeyType<'_> {
if self.use_iterator == 0 || self.use_iterator == 2 {
return self.a.key();
}
self.b.key()
}
fn value(&self) -> &[u8] {
if self.use_iterator == 0 || self.use_iterator == 2 {
return self.a.value();
}
self.b.value()
}
fn is_valid(&self) -> bool {
if self.use_iterator == u8::MAX {
false
} else if self.use_iterator == 0 {
self.a.is_valid()
} else {
self.b.is_valid()
}
}
fn next(&mut self) -> Result<()> {
if self.use_iterator == 0 {
// advance the first iterator because the second one wasn't used
if self.a.is_valid() {
self.a.next()?;
}
} else if self.use_iterator == 1 {
// advance the second iterator because the first one wasn't used
if self.b.is_valid() {
self.b.next()?;
}
} else if self.use_iterator == 2 {
// advance both
if self.a.is_valid() {
self.a.next()?;
}
if self.b.is_valid() {
self.b.next()?;
}
}
self.use_iterator = TwoMergeIterator::decide_which_iter_to_use(&self.a, &self.b);
Ok(())
}
fn num_active_iterators(&self) -> usize {
self.a.num_active_iterators() + self.b.num_active_iterators()
}
}
Now, this would have actually been enough at this point. However, the course defines two additional types of iterators to make changing things easier, so let’s just add those. However, the hierarchy of the iterators is the same as we saw in the above diagram. We will add 2 new layers but nothing fundamentally changed.
use std::{
io::{self, ErrorKind},
ops::Bound,
};
use anyhow::Result;
use bytes::Bytes;
use crate::{
iterators::{
merge_iterator::MergeIterator, two_merge_iterator::TwoMergeIterator, StorageIterator,
},
mem_table::MemTableIterator,
table::SsTableIterator,
};
/// Represents the internal type for an LSM iterator. This type will be changed across the tutorial for multiple times.
type LsmIteratorInner =
TwoMergeIterator<MergeIterator<MemTableIterator>, MergeIterator<SsTableIterator>>;
pub struct LsmIterator {
inner: LsmIteratorInner,
upper_bound: Bound<Bytes>,
is_valid: bool,
}
impl LsmIterator {
pub(crate) fn new(iter: LsmIteratorInner, upper_bound: Bound<Bytes>) -> Result<Self> {
let mut lsm_iter = Self {
is_valid: iter.is_valid(),
inner: iter,
upper_bound,
};
// when an iterator is first created, there is the possibility that
// the very first key-value pair is a tombstone so need to account for that
lsm_iter.skip_deleted_values()?;
Ok(lsm_iter)
}
// if the value associated with the key after calling next is an empty string
// this marks a tombstone. this key should be skipped so that the consumer
// of this iterator does not see it
fn skip_deleted_values(&mut self) -> Result<()> {
while self.inner.is_valid() && self.inner.value().is_empty() {
self.inner.next()?;
if !self.inner.is_valid() {
self.is_valid = false;
return Ok(());
}
match self.upper_bound.as_ref() {
Bound::Included(key) => {
if self.inner.key().raw_ref() > key {
//invalidate the iterator
self.is_valid = false;
}
}
Bound::Excluded(key) => {
if self.inner.key().raw_ref() >= key {
// invalidate the iterator
self.is_valid = false;
}
}
Bound::Unbounded => {}
}
}
Ok(())
}
}
impl StorageIterator for LsmIterator {
type KeyType<'a> = &'a [u8];
fn is_valid(&self) -> bool {
self.is_valid
}
fn key(&self) -> &[u8] {
self.inner.key().into_inner()
}
fn value(&self) -> &[u8] {
self.inner.value()
}
fn next(&mut self) -> Result<()> {
self.inner.next()?;
if !self.inner.is_valid() {
self.is_valid = false;
return Ok(());
}
match self.upper_bound.as_ref() {
Bound::Included(key) => {
if self.inner.key().raw_ref() > key {
//invalidate the iterator
self.is_valid = false;
}
}
Bound::Excluded(key) => {
if self.inner.key().raw_ref() >= key {
// invalidate the iterator
self.is_valid = false;
}
}
Bound::Unbounded => {}
}
self.skip_deleted_values()?;
Ok(())
}
fn num_active_iterators(&self) -> usize {
self.inner.num_active_iterators()
}
}
/// A wrapper around existing iterator, will prevent users from calling `next` when the iterator is
/// invalid. If an iterator is already invalid, `next` does not do anything. If `next` returns an error,
/// `is_valid` should return false, and `next` should always return an error.
pub struct FusedIterator<I: StorageIterator> {
iter: I,
has_errored: bool,
}
impl<I: StorageIterator> FusedIterator<I> {
pub fn new(iter: I) -> Self {
Self {
iter,
has_errored: false,
}
}
}
impl<I: StorageIterator> StorageIterator for FusedIterator<I> {
type KeyType<'a> = I::KeyType<'a> where Self: 'a;
fn is_valid(&self) -> bool {
if self.has_errored {
return false;
}
self.iter.is_valid()
}
fn key(&self) -> Self::KeyType<'_> {
self.iter.key()
}
fn value(&self) -> &[u8] {
self.iter.value()
}
fn next(&mut self) -> Result<()> {
if self.has_errored {
return Err(io::Error::new(ErrorKind::Other, "The iterator has errored").into());
}
if !self.is_valid() {
return Ok(());
}
match self.iter.next() {
Ok(_) => Ok(()),
Err(e) => {
self.has_errored = true;
Err(e)
}
}
}
fn num_active_iterators(&self) -> usize {
self.iter.num_active_iterators()
}
}
We are finally at a point where we can run a scan on the entire data store and get accurate results. So, let’s define the interface and implement it for that.
/// Create an iterator over a range of keys.
pub fn scan(
&self,
lower: Bound<&[u8]>,
upper: Bound<&[u8]>,
) -> Result<FusedIterator<LsmIterator>> {
// create the merge iterator for the memtables here
let state_guard = self.state.read();
let mut memtables = Vec::new();
memtables.push(Arc::clone(&state_guard.memtable));
memtables.extend(
state_guard
.imm_memtables
.iter()
.map(|memtable| Arc::clone(memtable)),
);
let mut memtable_iterators = Vec::new();
for memtable in memtables {
// create a memtable iterator for each memtable
let iterator = memtable.scan(lower, upper);
memtable_iterators.push(Box::new(iterator));
}
let memtable_merge_iterator = MergeIterator::create(memtable_iterators);
drop(state_guard);
// create the merge iterator for the SsTables here
let snapshot = {
let state_guard = self.state.read();
Arc::clone(&state_guard)
};
// retrieve the ids of the sstables
let sstable_ids = &*snapshot.l0_sstables;
let mut sstable_iterators: Vec<Box<SsTableIterator>> = Vec::new();
for sstable_id in sstable_ids {
let sstable = snapshot.sstables.get(&sstable_id).unwrap();
// need to skip building any iterators that cannot contain the key
if !self.range_overlap(lower, upper, sstable.first_key(), sstable.last_key()) {
continue;
}
let sstable_iter = match lower {
Bound::Included(key) => SsTableIterator::create_and_seek_to_key(
Arc::clone(sstable),
KeySlice::from_slice(key),
)?,
Bound::Excluded(key) => {
let mut iterator = SsTableIterator::create_and_seek_to_key(
Arc::clone(sstable),
KeySlice::from_slice(key),
)?;
if iterator.is_valid() && iterator.key().raw_ref() == key {
iterator.next()?;
}
iterator
}
Bound::Unbounded => SsTableIterator::create_and_seek_to_first(Arc::clone(sstable))?,
};
sstable_iterators.push(Box::new(sstable_iter));
}
let sstable_merge_iterator = MergeIterator::create(sstable_iterators);
let lsm_iterator = LsmIterator::new(
TwoMergeIterator::create(memtable_merge_iterator, sstable_merge_iterator)?,
map_bound(upper),
)?;
Ok(FusedIterator::new(lsm_iterator))
}
And here’s how we’d use the above interface by utilising Rust’s bounds.
lsm.put(b"a", "1");
lsm.put(b"b", "2");
let mut iter = lsm.scan(std::ops::Bound::Unbounded, std::ops::Bound::Unbounded)?;
let mut cnt = 0;
while iter.is_valid() {
println!(
"{:?}={:?}",
Bytes::copy_from_slice(iter.key()),
Bytes::copy_from_slice(iter.value()),
);
iter.next()?;
cnt += 1;
}
Recap
Congrats on making it this far in the post. To recap, here’s what we’ve covered:
- Writing user data to an in-memory buffer called the memtable
- Flushing data from the memtable to a sorted string table
- Servicing point and range queries via iterators
This was quite a lengthy post and involved a ton of code. If you want to play around with the engine to get a feel for it, clone the repo and run it locally with
cargo run --bin mini-lsm-cli -- --compaction none
You can run commands like
fill 1000 3000 -> put values within that range
get 1001 -> get a specific value
scan 1001 1005 -> scan a specific range