Zero-Copy Pages in Rust: Or How I Learned To Stop Worrying And Love Lifetimes
You can find the source code for the project here
Zero-copy is a way to elide CPU copies between the kernel and user space buffers that is particularly useful in high throughput applications like database engines. It makes a huge difference in performance under high load, particularly when your working set is no longer cache resident.
What Is Zero-Copy
Here is what a typical database engine looks like. For this post, focus on two copy boundaries: the OS boundary, and the path from the buffer pool into the layers above it.
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Execution Engine │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Transaction Manager │
└──────────┬─────────────┴─────────────────┬──────────────┘
│ │
┌──────────▼──────────┐ ┌────────────▼────────────┐
│ Lock Manager │ │ Log Manager │
└─────────────────────┘ └─────────────────────────┘
│ fresh copies into higher layers
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
└────────────────────────┬────────────────────────────────┘
│ copy at OS boundary
┌────────────────────────▼────────────────────────────────┐
│ Disk │
└─────────────────────────────────────────────────────────┘
Trying to build a high performance engine requires eliding any non-useful work as far as possible and copying data falls squarely in this category.
Think of each copy operation as an equivalent of memcpy()memcpy can actually cause pipeline stalls which is something you want to avoid in high perf applications. which requires the CPU to copy data from a source and put it into a destination. You’re spending cycles on non-essential work and this can cause eviction of hot data from CPU caches.
Here’s a great example of the lifecycle that a typical read or write operation goes through. All those CPU copies are useless work that are burning cycles.
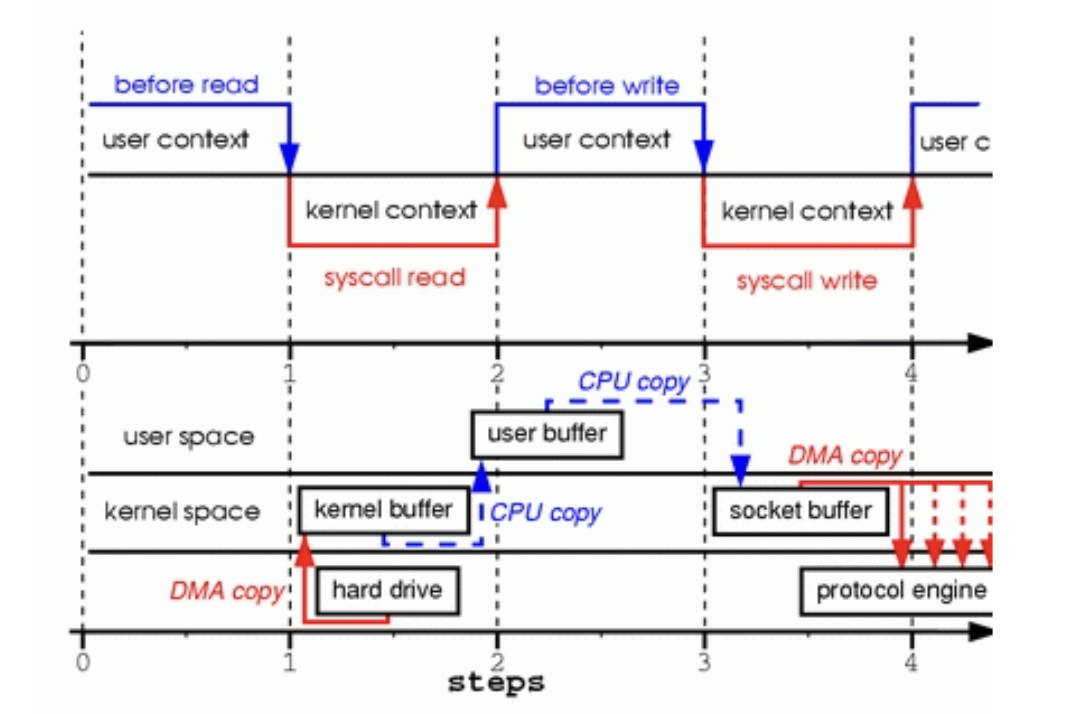 |
|---|
| Image taken from https://www.linuxjournal.com/article/6345 |
Now, let’s focus on eliminating copies at the layer between the buffer pool and disk first.
The Buffer Pool And Direct IO
Here’s a famous tirade from Linus Torvalds on the direct IO interface. He doesn’t like database developers.
The buffer pool opens and stores file descriptors with the open() syscall. When we call read() and write() on those file descriptors it goes through the whole cycle you saw earlier with copies between userspace, kernel and DMA.
An easy win here is to use direct IO with the O_DIRECT flagA large number of modern databases use this approach, although there are holdouts like Postgres.. This will force the application to bypass the OS page cacheThis assumes 64-bit DMA capable hardware. On systems with 32-bit DMA devices or confidential computing VMs (AMD SEV, Intel TDX), the kernel may silently introduce a SWIOTLB bounce buffer, reintroducing a CPU copy. See the Linux kernel docs on swiotlb..
O_DIRECT requires that the buffers submitted are pointer aligned, along with I/O length and file offset. In Rust, we guarantee the former with #[repr(align(4096))] on the buffer holding our page, and 4 KiB page-sized reads and writes at page-aligned offsets satisfy the rest. Without this, O_DIRECT reads or writes would often fail with EINVALHere’s a gist showing this in C — the first program uses malloc (not 4096-aligned) and the write fails, the second uses posix_memalign and succeeds..
Since we’re bypassing the kernel page cache we don’t get useful boosts like readahead or write coalescing but this is exactly why a buffer pool is so important in a database.
The buffer pool is a replacement for the OS page cache designed with specific workloads in mind. It’s always helpful to think of this in terms of mechanism + policy.
Mechanism: A fixed size page table which serves page requests for the layers above and evicts some pages to make room for others.
Policy: A way to decide which page to evict (eviction policy)
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
│ │
│ TableScan / IndexScan / BTreeScan │
│ (iterates rows, calls next(), get_value()) │
└────────────────────────┬────────────────────────────────┘
│ uses
┌────────────────────────▼────────────────────────────────┐
│ Transaction │
│ │
│ tx_id | ConcurrencyManager | RecoveryManager │
└────────────────────────┬────────────────────────────────┘
│ pin() / unpin()
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Frame 0 │ │ Frame 1 │ │ Frame 2 │ ... │
│ │ │ │ │ │ │ │
│ │ file:3 │ │ file:7 │ │ empty │ │
│ │ pins: 1 │ │ pins: 0 │ │ pins: 0 │ │
│ │ │ │ │ │ │ │
│ │ 4KB data │ │ 4KB data │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ policy: LRU | CLOCK | SIEVE │
└────────────────────────┬────────────────────────────────┘
│
│
┌────────────────────────▼────────────────────────────────┐
│ Disk │
│ │
│ [ file:1 ] [ file:3 ] [ file:7 ] [ file:9 ] │
└─────────────────────────────────────────────────────────┘
Choosing the right policy for your system depends on the characteristics of your workload but most systems typically go with CLOCK which is an LRU approximation. Here’s a non-exhaustive list of replacement policies used in buffer pools.
O_DIRECT removes the copy at the OS boundary. The next problem is avoiding fresh copies once the page is already in the buffer pool.
Eliminating Copies From The Read Path
So far, zero-copy has meant removing copies between the kernel and the buffer pool. From here on, I’m going to broaden it slightly to mean removing redundant copies inside the engine too.
Rust has a great and terrible way to avoid dealing with copies of data - references. It’s great because it’s a single character (&), it’s terrible because now we have to learn to deal with lifetimes.
The simplest way to think about lifetimes is that you are proving to the compiler that any reference held by type A will not outlive the data it points to.
Let’s start with defining the raw bytes for a single page like this
pub struct PageBytes {
bytes: [u8; PAGE_SIZE_BYTES as usize],
}
Now, we’ll define the data that is held within a single buffer pool frame. The RwLock<T> type here is our page latch.
#[derive(Debug)]
pub struct BufferFrame {
page: RwLock<PageBytes>,
}
Now, we’re going to store this frame’s data inside a PageReadGuard.
// To keep the example small, the next type is schematic rather than literal.
// I'm using it to show the ownership tradeoff, not the exact implementation
// details of `RwLockReadGuard`.
/// Read guard providing shared access to a pinned page.
pub struct PageReadGuard {
page: PageBytes,
}
This version is simple to model, but it bakes copying into the design. If every higher-level page object owns its own PageBytes, then constructing those objects from buffer-pool storage means materializing fresh owned values.
What we actually want is not ownership, but a borrowed view into bytes that already live somewhere else. We can model that by introducing a lifetime.
pub struct PageReadGuard<'a> {
page: &'a PageBytes,
}
With this lifetime annotation, we are proving to the compiler that PageReadGuard will not outlive PageBytes, which means higher-level page objects can become views into existing bytes rather than owned copies.
In the real implementation, the field is RwLockReadGuard<'a, PageBytes> rather than &'a PageBytes, but the ownership story is the same: the guard borrows the page bytes instead of owning them, and our wrapper carries that borrow forward.
pub struct PageReadGuard<'a> {
page: RwLockReadGuard<'a, PageBytes>
}
Typical database engines have two core page types - heap and btree pages. So let’s focus on the former. The structure of the page is going to be a standard slotted page layout.
At this point, the bytes are already borrowed through PageReadGuard<'a>. Now, the question is where the guard should live and where the parsed references into the page should live.
The most natural thing to try is to keep everything in one struct.
struct HeapPage<'a> {
guard: PageReadGuard<'a>,
header: &'a [u8],
line_pointers: &'a [u8],
record_space: &'a [u8],
}
This leads us to the classic self-referential struct issue in Rust, which makes pointer invalidation very hard. Imagine for a moment, you have a struct and it has two fields - A and B, with B pointing to A. Now, your struct A moves. What does B point to? It’s going to continue pointing to where A was but that’s invalid and would lead to UB. There are ways around this in Rust with Pin, unsafe raw pointers, Arc pointers and external crates like ouroboros. But, all of these have overhead associated with them.
So, the next thing to try is to separate ownership of the guard from the parsed view into the page.
pub struct HeapPage<'a> {
guard: PageReadGuard<'a>,
}
pub struct HeapPageView<'a> {
header: &'a [u8],
line_pointers: &'a [u8],
record_space: &'a [u8],
layout: &'a Layout,
}
let page = HeapPage::new(guard);
let view = HeapPageView::new(&'a page, layout); // borrows from page and page stays alive on stack
This works but runs into an issue when we want to mutate the bytes. Imagine that we want to insert a record into the heap page. This requires mutating record_space and also mutating line_pointers. Now, the bounds of both might have changed which means we have stale references in our struct. We need to drop the struct and re-create it again. While it is cheap, it’s a leaky abstraction.
A better form would be to do the following
pub struct HeapPage<'a> {
guard: PageReadGuard<'a>,
}
pub struct HeapPageView<'a> {
header: &'a [u8],
body_bytes: &'a [u8],
layout: &'a Layout,
}
let page = HeapPage::new(guard);
let view = HeapPageView::new(&'a page, layout); // borrows from page and page stays alive on stack
In slotted pages, the header size is fixed and anytime we want to perform some operation we re-parse the body bytes using information from the header and get an accurate view into the bytes.
But, the above requires keeping the page and view alive on the stack and leaks implementation details up to the query layer. Once again, a leaky abstraction.
The version I went with flips this around.The old computer science move: “Any problem in computer science can be solved with another level of indirection”. To make that concrete, a slotted page is divided into the header, the line pointers and the record space, so we’ll store those parsed references in HeapPage and keep the PageReadGuard in HeapPageView.
pub struct HeapHeaderRef<'a> {
bytes: &'a [u8],
}
struct LinePtrBytes<'a> {
bytes: &'a [u8],
}
struct LinePtrArray<'a> {
bytes: LinePtrBytes<'a>,
len: usize,
capacity: usize,
}
struct HeapRecordSpace<'a> {
bytes: &'a [u8],
base_offset: usize,
}
struct HeapPage<'a> {
header: HeapHeaderRef<'a>,
line_pointers: LinePtrArray<'a>,
record_space: HeapRecordSpace<'a>,
}
pub struct HeapPageView<'a> {
guard: PageReadGuard<'a>,
layout: &'a Layout,
}
All of them share the exact same lifetime of 'a, which means that any of these references held by another type will not outlive the type.
And all of these types are references into the exact same set of bytes held by PageBytes in the BufferFrame.
PageBytes (owned by BufferFrame)
┌─────────────────────────────────────────────────────┐
│ Header (34 bytes) │
│ page_type | slot_count | free_lower | free_upper .. │
├─────────────────────────────────────────────────────┤
│ Line Pointers (grows →) │
│ [ slot 0 ] [ slot 1 ] [ slot 2 ] ... │
├─────────────────────────────────────────────────────┤
│ Free Space │
├─────────────────────────────────────────────────────┤
│ Record Space (grows ←) │
│ ... [ tuple 2 ] [ tuple 1 ] [ tuple 0 ] │
└─────────────────────────────────────────────────────┘
│ │ │
HeapHeaderRef<'a> LinePtrArray<'a> HeapRecordSpace<'a>
│ │ │
└───────────────┴────────────────────┘
│
HeapPage<'a> ←─────────────────────────┐
│
built from
│
HeapPageView<'a>
┌──────────────────────────┐
│ guard: PageReadGuard<'a> │
│ layout: &'a Layout │
└──────────────────────────┘
│
owns the lock on
│
PageBytes in BufferFrame
The link between them is a method on HeapPageView that constructs a HeapPage whenever some operation needs an interpreted view of the page bytes.
impl<'a> HeapPageView<'a> {
fn build_page(&'a self) -> HeapPage<'a> {
HeapPage::new(self.guard.bytes()).unwrap()
}
pub fn row(&self, slot: SlotId) -> Option<LogicalRow<'_>> {
let view = self.build_page();
let mut current = slot;
loop {
match view.tuple_ref(current)? {
// code elided for simplicity
}
}
}
}
impl<'a> HeapPage<'a> {
fn new(bytes: &'a [u8]) -> SimpleDBResult<Self> {
// Use shared parsing logic from PageKind trait
let layout = Self::parse_layout(bytes)?;
let header = HeapHeaderRef::new(layout.header);
// Additional heap-specific validation
let free_upper = header.free_upper() as usize;
let page_size = PAGE_SIZE_BYTES as usize;
if free_upper < header.free_lower() as usize || free_upper > page_size {
return Err("heap page free_upper out of bounds".into());
}
let page = Self::from_parts(header, layout.line_ptrs, layout.records, layout.base_offset);
assert_eq!(
page.slot_count(),
header.slot_count() as usize,
"slot directory length must match header slot_count"
);
Ok(page)
}
}
When the query layer wants to read something from the data pages, it will get a HeapPageView and any operation on the HeapPageView that requires access to some logical segment of data will construct a HeapPage which understands how the bytes on the page are laid out.
Now, you’re probably wondering about the cost of reconstructing the HeapPage each time. It’s actually really cheap because it’s composed entirely of arithmetic operations sprinkled with a few panics in case some invariants aren’t met. And arithmetic operations are extremely cheap for the CPU to perform, especially when compared to memcpy() operations.
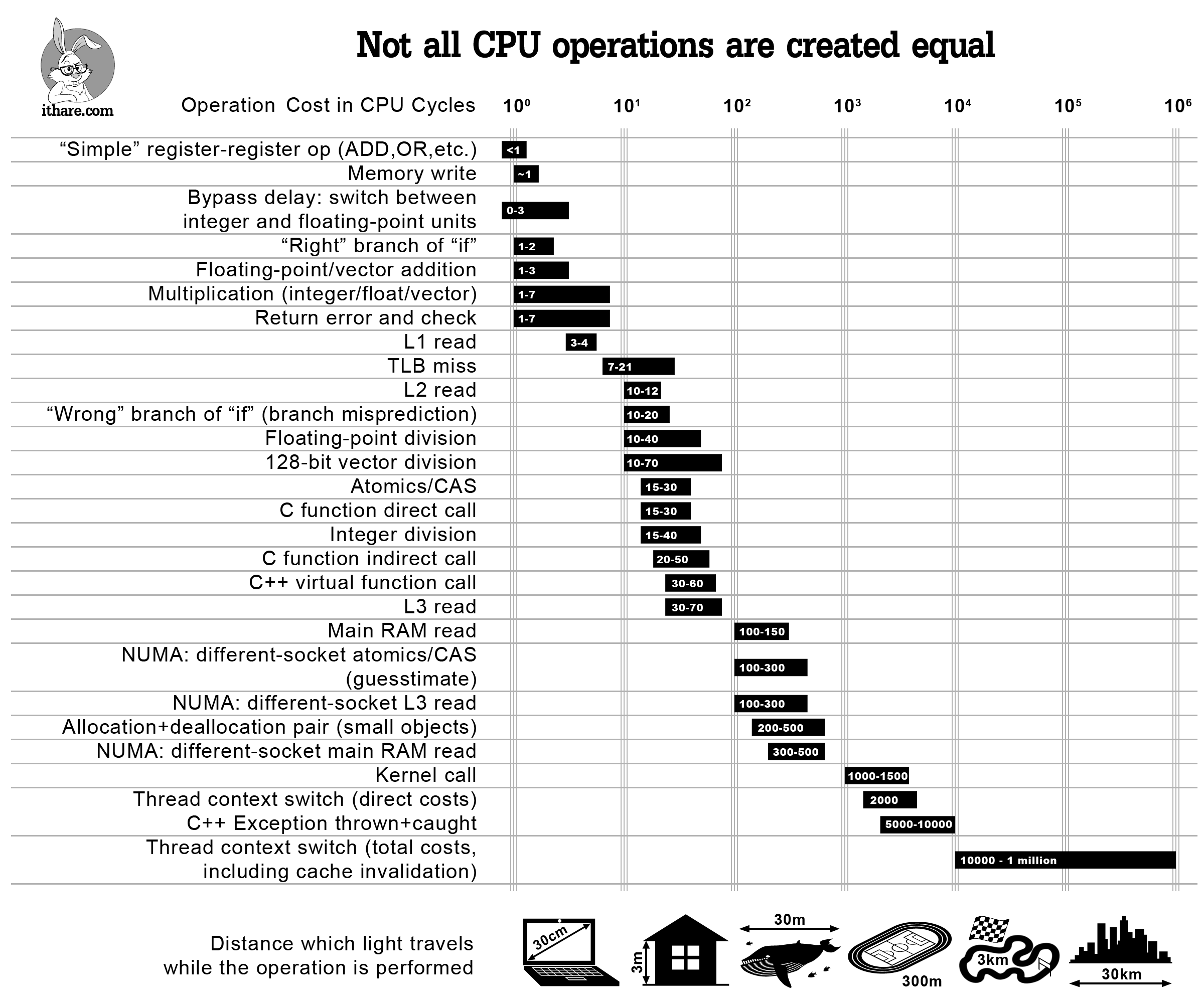 |
|---|
| Not all CPU operations are created equal. Source: ithare.com, via Andrew Kelley’s talk on Data Oriented Design |
Eliminating Copies From The Write Path
In the previous section we saw PageReadGuard, HeapPage and HeapPageView which collectively constitute the read side path of the page. However, Rust has the principle of aliasing XOR mutability and this means that we either get multiple &T or a single &mut T. Everything we saw above is on the &T path and we need a &mut T path.
/// Write guard providing exclusive access to a pinned page.
pub struct PageWriteGuard<'a> {
page: RwLockWriteGuard<'a, PageBytes>,
}
pub struct HeapPageMut<'a> {
header: HeapHeaderMut<'a>,
body_bytes: &'a mut [u8],
}
pub struct HeapPageViewMut<'a> {
guard: PageWriteGuard<'a>,
layout: &'a Layout,
}
impl<'a> HeapPageViewMut<'a> {
fn build_mut_page(&mut self) -> SimpleDBResult<HeapPageMut<'_>> {
HeapPageMut::new(self.guard.bytes_mut())
}
pub fn insert_tuple(&mut self, tuple: &[u8]) -> SimpleDBResult<SlotId> {
let mut page = self.build_mut_page()?;
page.insert(tuple)
}
}
Now, we abide by Rust’s aliasing rules and if we have a BufferFrame, we can either acquire the read latch multiple times and build the read path or acquire the write latch and build the write path.
BufferFrame
RwLock<PageBytes>
│
┌──────────┴──────────┐
│ │
read_page() write_page()
│ │
RwLockReadGuard RwLockWriteGuard
(shared, N readers) (exclusive, 1 writer)
│ │
PageReadGuard PageWriteGuard
&'a [u8] &'a mut [u8]
│ │
HeapPage HeapPageMut
(borrows &'a [u8]) (borrows &'a mut [u8])
│ │
HeapPageView<'a> HeapPageViewMut<'a>
And, of course, Rust’s borrow checker makes use-after-unpin a compile error, not a runtime hazard.
There’s one more asymmetry worth noting. HeapPage splits the bytes into three fields (header, line pointers, record space) because reads are idempotent and those boundaries never shift.
HeapPageMut can’t do the same: a single insert moves both free_lower and free_upper, making any pre-split reference immediately stale. So HeapPageMut keeps a single body_bytes: &mut [u8] and re-derives sub-regions from the header on each operation. Rust prevents aliased mutable access, but the deeper invariant that split points must always match the header has to be enforced through design.
Nested Borrows
If you’ve noticed, so far we’ve been using only a single lifetime of 'a, which makes sense because we’ve been borrowing everything from the same set of underlying bytes.
But, we’ve actually been imprecise and let the compiler handle some of the drudgery for us. The chain of borrows so far has been:
PageBytes → RwLock{Read,Write}Guard<'a> → Page{Read,Write}Guard<'a> → HeapPage[Mut]<'a> → HeapPageView[Mut]<'a>
Each successive borrow nests within the previous one but the compiler allows us to do all of this with a single lifetime because of lifetime variance.
The crux of lifetime variance is that shared references are covariant and exclusive references are invariant. Another way this is frequently expressed is that &T is covariant over 'a and &mut T is invariant over 'a.
For covariant lifetimes, Rust can shorten a longer-lived &T into a shorter-lived &T when needed, which allows us to elide the nested lifetimes and let the compiler infer the intermediate lifetimes for us.
Mutable borrows are less forgiving because mutation makes those coercions much stricter. With &mut T, Rust can’t be as flexible about the inner lifetime without risking that a shorter-lived reference gets written into a place that promised to hold a longer-lived one.
Here’s a concrete example that demonstrates the asymmetry. We define a struct with two lifetimes and try to shorten one in a function:
struct Inner<'a> {
data: &'a [u8],
}
struct Outer<'short, 'long> {
inner: &'short Inner<'long>,
}
fn shorten<'long, 'short>(outer: Outer<'short, 'long>) -> Outer<'short, 'short> { outer }
This compiles because &T is covariant over 'long. The function can coerce a reference where the data outlives the borrow.
Now, change the outer reference to mutable:
struct Outer<'short, 'long> {
inner: &'short mut Inner<'long>,
}
fn shorten<'long, 'short>(outer: Outer<'short, 'long>) -> Outer<'short, 'short> { outer }
This fails to compile. &mut T is invariant over its lifetime parameter — it cannot be shortened even when the data outlives the borrow. The lifetimes must match exactly.
This is exactly what happens in HeapPageViewMut::row_mut() and the construction of LogicalRowMut:
pub struct LogicalRowMut<'row, 'page: 'row> {
view: &'row mut HeapPageViewMut<'page>,
}
impl<'a> HeapPageViewMut<'a> {
/// Decodes the live tuple at `slot` into a `LogicalRowMut` for editing.
/// Changes are written back to the page automatically when the returned value is dropped.
pub fn row_mut<'row>(
&'row mut self,
slot: SlotId,
) -> SimpleDBResult<Option<LogicalRowMut<'row, 'a>>> {
// code elided for simplicity
Ok(Some(LogicalRowMut {
view: self,
slot,
values,
layout,
dirty: false,
}))
}
}
'page is the lifetime of the underlying page view, which already borrows the pinned page bytes. 'row is the shorter lifetime of one exclusive edit session on top of that view. The relation 'page: 'row says that the page view has to stay valid for at least as long as the mutable row editor borrowing it.
Page bytes in BufferFrame
┌─────────────────────────────────────────────────────────────┐
│ header │ line pointers │ free space │ tuple 2 │ tuple 1 │… │
└─────────────────────────────────────────────────────────────┘
<---------------------- borrowed for 'page ---------------------->
one call to row_mut()
│
▼
LogicalRowMut<'row, 'page>
┌─────────────────────────┐
│ edits one logical row │
└─────────────────────────┘
<---- borrowed for 'row --->
Constraint: 'page : 'row
The Cost Of Safe Abstractions
The split into separate read and write types has a real ergonomic cost. HeapPageViewMut doesn’t automatically get HeapPageView’s read methods. In Rust’s standard library, &mut Vec<T> coerces to &Vec<T> automatically via Deref, so mutable references get all immutable methods for free.
This works because Vec<T> is backed by a single raw pointer internally. It implements Deref<Target=[T]> and DerefMut<Target=[T]> to give you either a &[T] or &mut [T]. From one pointer, the borrow checker decides at the call site whether you get a shared or exclusive slice based on how you borrowed it. The unsafe is inside Vec, audited once and invisible to callers.
pub struct Vec<T, #[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global> {
buf: RawVec<T, A>,
len: usize,
}
#[stable(feature = "rust1", since = "1.0.0")]
impl<T, A: Allocator> ops::Deref for Vec<T, A> {
type Target = [T];
#[inline]
fn deref(&self) -> &[T] {
self.as_slice()
}
}
pub const fn as_slice(&self) -> &[T] {
unsafe { slice::from_raw_parts(self.as_ptr(), self.len) }
}
Our design can’t do this. PageReadGuard and PageWriteGuard hold fundamentally different types — RwLockReadGuard and RwLockWriteGuard — that can’t be unified into a single raw pointer. The RwLock enforces the read/write distinction at runtime, so it has to be reflected as two distinct types at compile time. Any read method you want on HeapPageViewMut has to be written explicitly.
This is the tradeoff in Rust API design. There is no unsafe, and there is a clear separation of capabilities, but the ergonomics aren’t as nice as the ones unsafe-backed types get for free.
Conclusion
By the end, the path looks more like this:
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Execution Engine │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Transaction Manager │
└──────────┬─────────────┴─────────────────┬──────────────┘
│ │
┌──────────▼──────────┐ ┌────────────▼────────────┐
│ Lock Manager │ │ Log Manager │
└─────────────────────┘ └─────────────────────────┘
│ borrowed views over page bytes
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
└────────────────────────┬────────────────────────────────┘
│ `O_DIRECT` removes this copy
┌────────────────────────▼────────────────────────────────┐
│ Disk │
└─────────────────────────────────────────────────────────┘
O_DIRECT removes the copy between disk and the buffer pool, and the page/view design removes fresh copies above the buffer pool by turning higher-level page objects into borrowed views over bytes that are already pinned in memory.
To me, the interesting part of this design is that it moves ownership into one place, the buffer pool. Everything above that is about views over the same set of bytes. This comes at the price of API ergonomics though. I had to structure the zero-copy page access so that the compiler can see the same invariants I care about. While it litters the code with lifetime annotations it eliminates a certain class of bugs and avoids redundant data movement.