3PC
Introduction
Last time I discussed the 2PC protocol and I want to discuss it’s lesser known cousin, the 3PC protocol.
The 3PC protocol seems to be more of an intellectual curiosity than anything else because it hasn’t seen very widespread adoption in real world systems. This is due to a variety of reasons including the complexity of the algorithm.
The Phases
There are 3 primary phases of the protocol:
- The CanCommit phase
- The PreCommit phase
- The DoCommit phase
Each of these phases represent a message that is sent from the coordinator to every participant that is currently part of the same network.
Now, the main difference from the 2PC protocol comes in the form of adding timeouts between each of the stages.
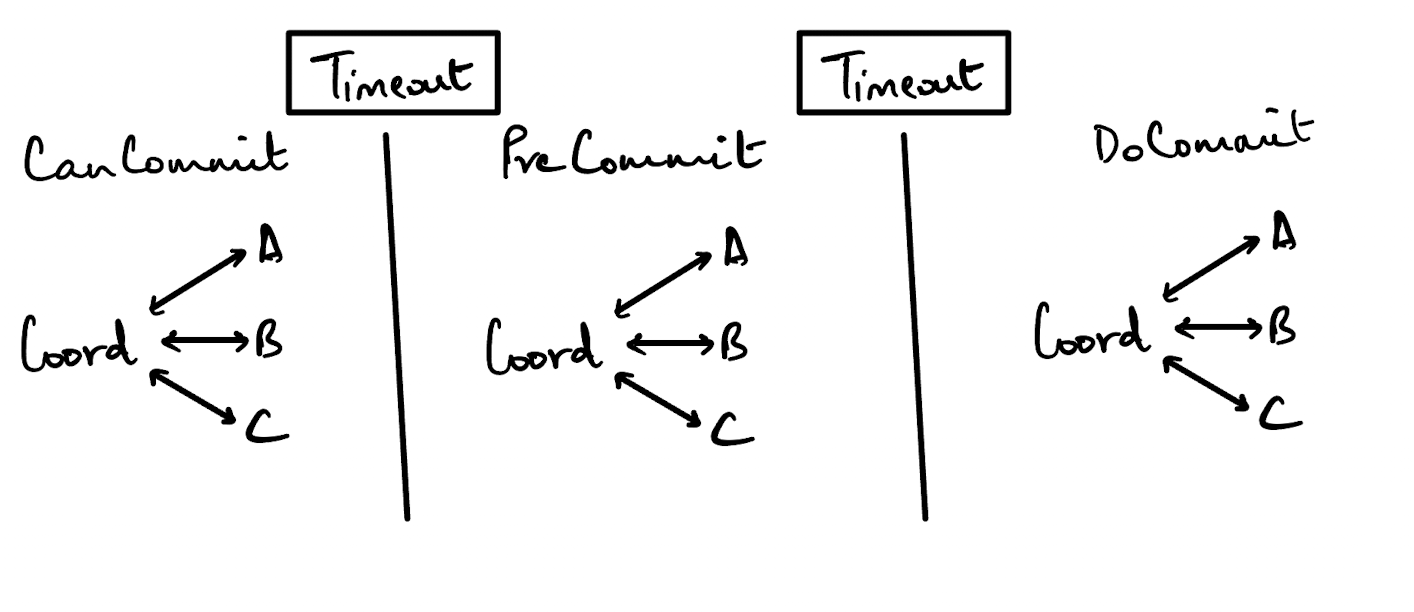
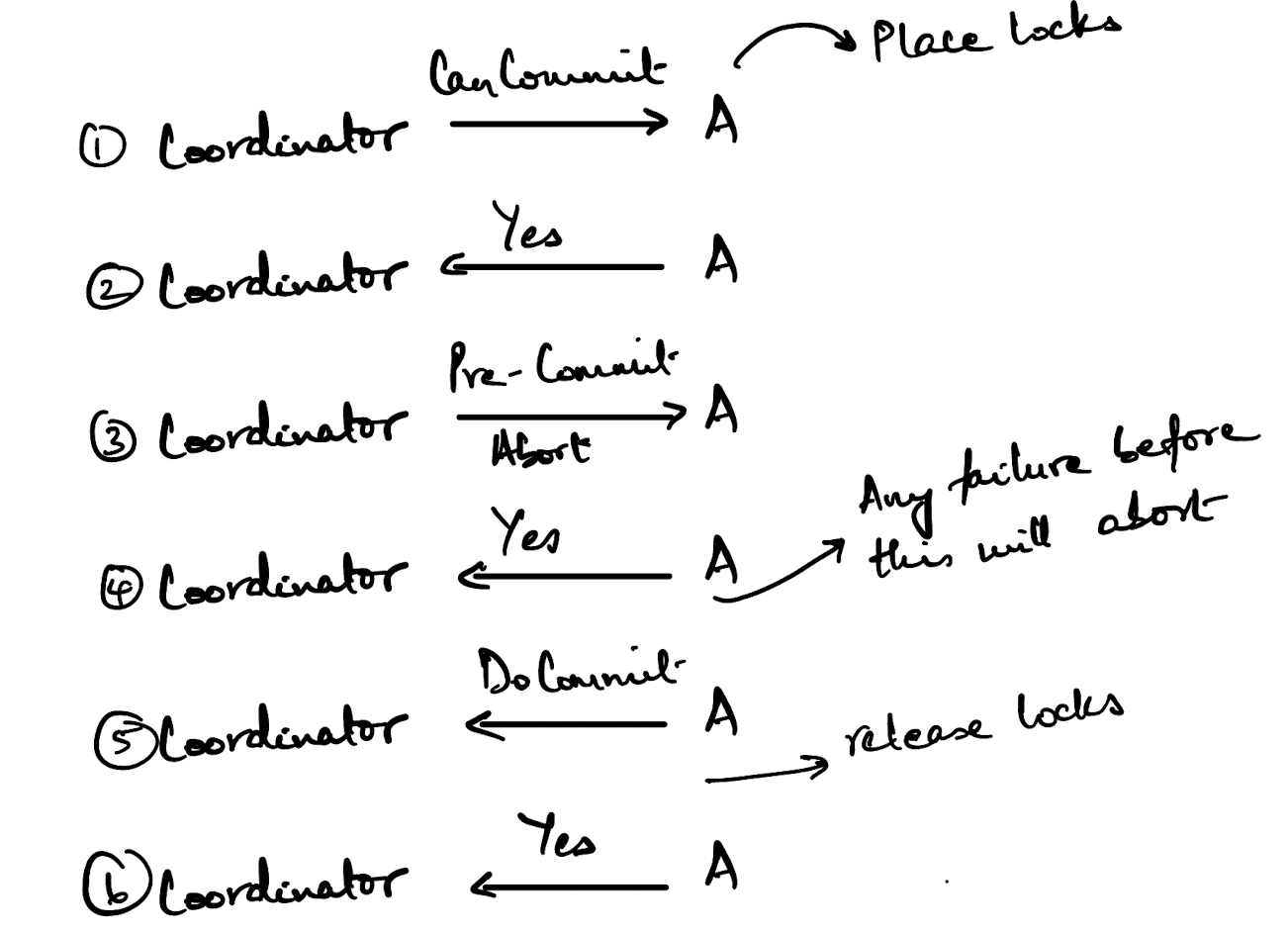
So, to kick things off the coordinator sends out a CanCommit message to each of the nodes. The coordinator then immediately starts a timeout interval. If it doesn’t receive a response from any one of the nodes within that interval, it assumes that node has failed and will abort the transaction. The nodes check whether whatever resources need to be locked can be locked and applies those locks.
If the node replies to the CanCommit message with a YES, then the node will start a timeout interval. If the node in turn doesn’t receive a PreCommit message from the coordinator within that interval, it assumes that the coordinator has failed and aborts the transaction.
Once the node receives a PreCommit message, it will make some preliminary writes to it’s local storage and perhaps to it’s WAL (I’m not a 100% sure here because this seems very implementation dependent). Once these writes are done, it will reply with a YES or NO depending on whether or not the writes were completed.
Now, once the DoCommit message is sent from the coordinator to each node, this is a confirmation that preliminary writes that were done can be applied to durable storage and the locks can be released. Once the locks are released, the node sends an acknowledgement to the coordinator.
Failure Modes
Now, comes the interesting bit - the failure modes. This also helps answer why this protocol is any better than 2PC.
The Coordinator Failing
In 2PC, if the coordinator fails after the prepare phase, the nodes are stuck in an uncertain state. They would have acquired the locks on the resources but will have no idea what to do next. One of the solutions could perhaps be to wait for a backup leader to come online, determine what the state of the previous transaction is and continue from there.
This is one of the primary advantages of 3PC. If the leader node crashes after sending out a PreCommit message but before sending out a DoCommit message, then the nodes have two options:
- Wait for the leader node to come back online or a backup leader
- Start a termination protocol
The Termination Protocol
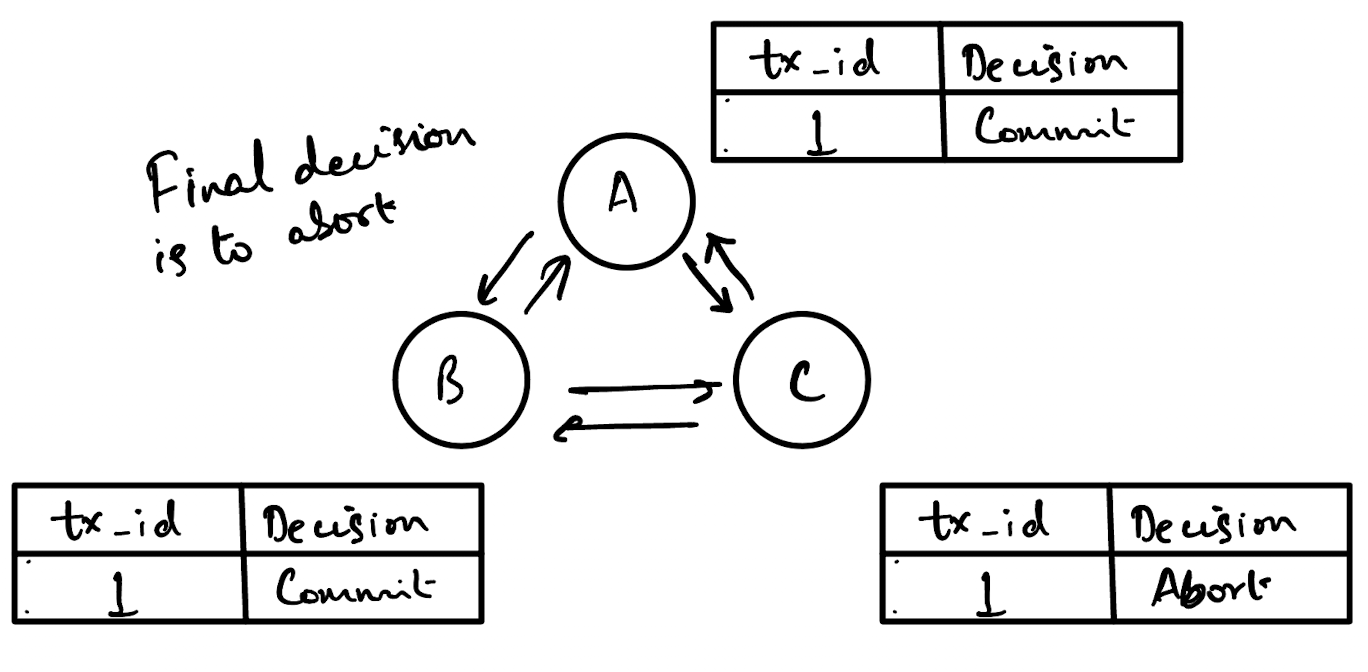
The termination protocol is where all the nodes discuss with each other what they replied to the last PreCommit message sent by the leader node.
The fundamental essence of this is essentially a consensus protocol (Raft and Paxos are more complicated versions of this). If there are multiple nodes each with a different value for the same key, how do you decide which value is correct?
Again, the solutions to this would probably be implementation dependent. But, the simplest version would be an abort if any node aborts version. That is, if any node voted no to the PreCommit message, all nodes will abort the transaction. This ensures consistent state with relatively little complexity overhead.
What is a far more interesting question is how do nodes communicate with each other to determine what outcome to take?
Communication In Termination
There are a couple of different options:
- Communication via a central ledger (ala Zookeeper, etcd, consul etc.)
- Communication via a gossip protocol
- Communication via some other form of broadcast
Each of these communication patterns ends up achieving the same goal, which is disseminating information among nodes to determine what direction to take.
Of course, each of these communication patterns introduce their own set of failures. For instance, depending on a central ledger like ZooKeeper introduces a single point of failure. If the ledger node goes down, how do nodes communicate with each other? The default would be to abort if they cannot reach each other within some pre-defined timeout.
Having said that, this termination protocol is the primary reason 3PC is preferred over 2PC. It doesn’t block in the case of a leader node failure.
2PC With Termination Protocol
A silly question that occurred to me (and I tend to have a lot of silly questions) was, why can’t we just add the termination protocol to 2PC?
There is a prepare phase after which if the leader fails, the entire transaction is blocked. Why not include a termination protocol right there to allow nodes to carry forward.
The answer, of course, is that the leader hasn’t issued a decision yet. The prepare phase is only about collecting votes from nodes to determine if the transaction can be carried out. The leader has yet to decide if the transaction should be carried out.
This is, of course, different from 3PC where there is an explicit stage where the leader collects votes and then issues a decision before asking nodes to commit that decision.
Network Partition
This is the achilles heel of 3PC, where the protocol really fails.
Imagine the following scenario
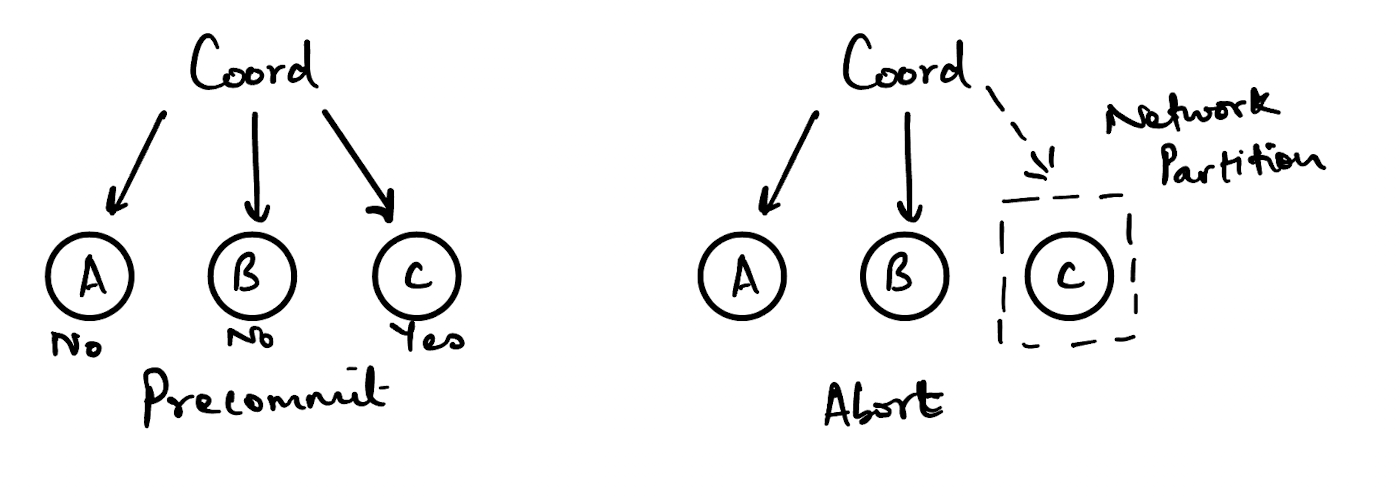
The coordinator sends out a pre-commit message to the three nodes - A, B & C.
Nodes A and B find that they cannot carry out the associated action and they reject it. Node C can and carries it out.
However, before the coordinator can send out an abort message to all three nodes, a network partition separates node C from the rest.
Now, node C is unaware of any further decisions taken by the coordinator and after the timeout exceeds it’s limit, C will independently decide to commit the transaction.
Now, one of the things I am unsure of is in the presence of a termination protocol, why would C choose to commit? Shouldn’t C choose to fail because it cannot reach any other node?
Once the network partition heals, C will come back online but will have a transaction committed that the other nodes will not and the system will be in an inconsistent state.
Adoption
One of the strangest things about 3PC is the relative lack of adoption in systems, despite having an obvious advantage over 3PC.
It’s obviously more complex to implement and involves the use of timeouts, which might be hard to maintain and debug, but given that it so clearly unblocks transactions, you would assume that it should see more widespread adoption.
Another drawback of 3PC is the additional latency due to the increased number of rounds of messages.
On a personal note, I wonder if the network partitions leading to an inconsistent state is a bigger problem than it seems. It’s one of those silent failures that might be a killer.
Another silly question I had while writing this was whether clock skew would affect the timeout process between nodes. But, it wouldn’t because the timeout is started by each node individually, so it would be local to that node.
3PC And MVCC
Usually, when you read about 3PC (or 2PC for that matter), the protocol discusses locks that are placed on resources that are currently involved in any transaction.
This led me to wonder how it would work in cases where locks aren’t traditionally employed for writes (like MVCC, which maintains multiple versions of an object). I imagine in this scenario, the PreCommit phase would involve writing a new version of an object but not committing it. Any other transaction that tried to write a new version of the same object would find that it was blocked because it couldn’t “lock” that resource.
During the Commit phase, that write would be made visible by committing the version of the object created during the PreCommit phase, post which new writes to that object could be performed.